We all have secrets. Some are small secrets which we barely hide (sometimes I roll through stop signs on my bike). Others are so sensitive that we don’t even want to think about them (serverless actually has servers).
Managing and securing secrets in your applications have similar dimensions! As a result, handling a random 3rd party API key is different from handling the root signing key for an operating system or nuclear launch codes.
This work is a fundamental requirement for any production-quality software system. Unfortunately, AWS doesn’t make it easy to select a secrets management tool within their ecosystem. For Serverless developers, this is even more difficult! Lambda is simply one service in a constellation of multiple supporting services which you can use to control application secrets. This guide lays out the most common ways to store and manage secrets for Lambda, the performance impacts of each option, and a framework for considering your specific use cases.
Quick best practices primer
Plaintext secrets should NEVER be hardcoded in your application code or source control. Typically you want to follow the principle of least privilege and limit the access of any runtime secret to only the runtime environment (Lambda, in this case).
This means passing references or encrypted data to configuration files or infrastructure as code tools whenever possible. It also means that decrypting or fetching secrets from a secure storage system at runtime will be the most secure option. This post is geared to deploying your Lambda applications along this dimension.
Lambda Secret Options
Within Lambda, there are four major options for storing configuration parameters and secrets. They are:
- Lambda Environment Variables
- AWS Systems Manager Parameter Store (Formerly known as Simple Systems Manager, or SSM)
- AWS Secrets Manager
- AWS Key Management Service
This post will rate each option along the following dimensions:
- Ease of use
- Cost
- Auditability
- Rotation Simplicity
- Capability
We’ll also cover the AWS Lambda Parameter and Secret extension, which is used to retrieve secrets from both Parameter Store and Secrets Manager from within a Lambda function.
Then, we’ll consider several example secrets with various blast radii, and decide which service best suits our needs.
Service breakdown Tl;dr
| |
Ease of Use |
Cost |
Auditability |
Rotation Complexity |
Capability |
| Environment Variables |
Easiest |
Free! |
Poor |
Requires UpdateFunctionConfiguration or deployment |
Encrypted at rest Decrypted when getFunctionConfiguration called.
Limited to 4KB total |
| Parameter Store Standard |
Some assembly required |
Free storage
Free calls up to 40 calls/second.
$0.05/10,000 calls after |
Good |
Easy manual rotation, not automatic |
4KB size limit |
| Parameter Store Advanced |
Some assembly required |
$0.05 per month per secret.
$0.05/10,000 calls |
Good |
Easy manual rotation, not automatic |
Supports TTL for secrets. 8KB size limit |
| Secrets Manager |
Some assembly required |
$0.40 per secret per month $0.05/10,000 calls.
30 day free tier. |
Good |
Easiest & Automatic
Built into the product |
Largest binary size, 65KB per secret |
| Key Management Service (KMS) |
Most work |
$1 per key per month $0.03/10,000 requests |
Good |
Depends on ciphertext storage.
Easy with DynamoDB/S3, more manual with env vars. |
Most flexible option.
4KB per encrypt operation.
Binary size is limited by storage mechanism.
Roll your own Secrets Manager or Parameter Store. |
Lambda Environment Variables
Environment variables in Lambda are where most folks start out in their journey. They’re baked right in, and can be fetched easily (using something like process.env.MY_SECRET for Node or os.environ.get('MY_SECRET') for Python). Unfortunately they are not the most secure option.
However one common misconception is that environment variables are stored as plain text by AWS Lambda. This is false.
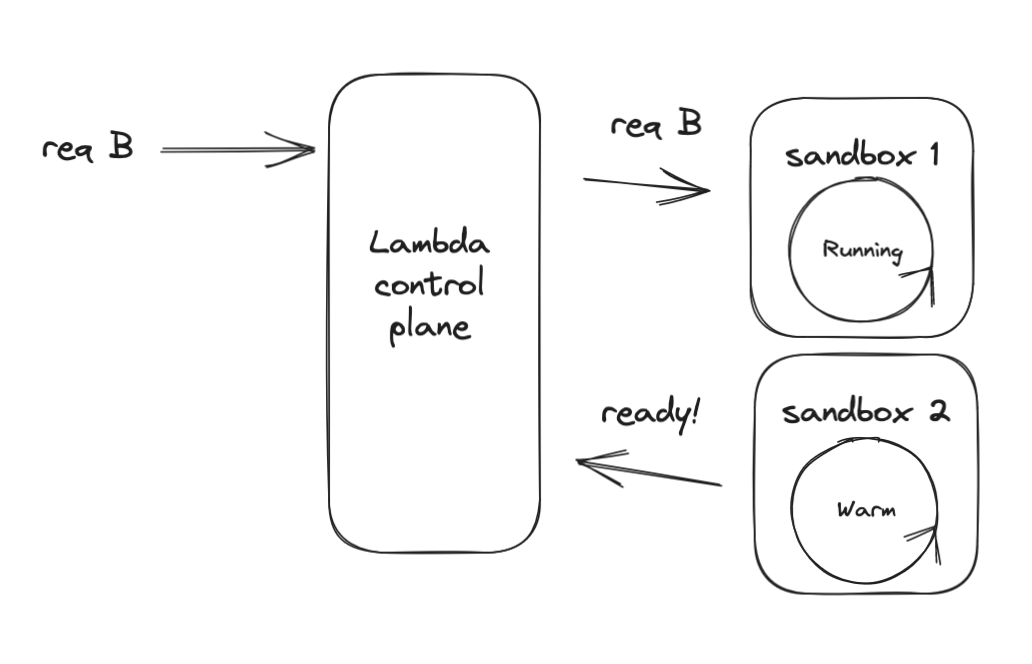
Lambda environment variables are encrypted at rest, and only decrypted when the Lambda Function initializes, or you take an action resulting in a call to GetFunctionConfiguration. This includes visiting the Environment Variables section of the Lambda page in the AWS Console. It startles some people to see their secrets on this page, but you can easily prevent this by denying lambda:GetFunctionConfiguration, or kms:Decrypt permissions from your AWS console user.
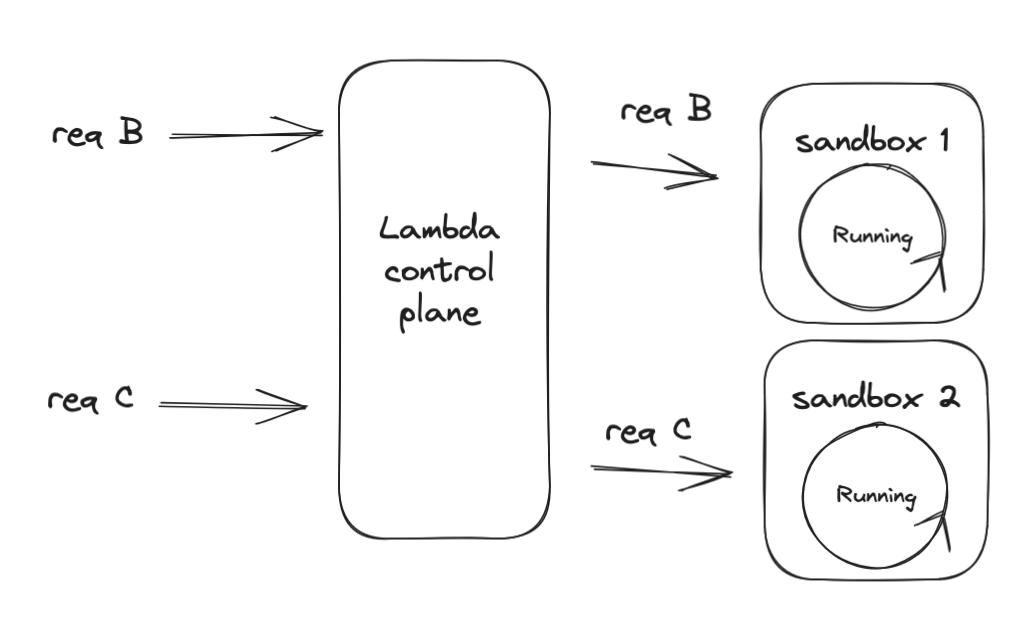
Auditability is another challenge of Lambda environment variables. For the principle of least privilege to be effective, we should limit access to secrets only to when they are needed. To ensure this is followed, or investigate and remediate a leaked secret, we need to know which Lambda function used a specific secret and at what time.
Environment variables are automatically decrypted and injected into every function sandbox upon initialization. Given that CloudTrail reflects one call to kms:Decrypt, I presume the entire 4KB environment variable package is encrypted together. This means you lack the ability to audit an individual secret - it’s all or nothing.
If you’re in a regulated environment, or otherwise distrust Amazon; you can create a Consumer-Managed Key (CMK) and use that to encrypt your environment variables instead.
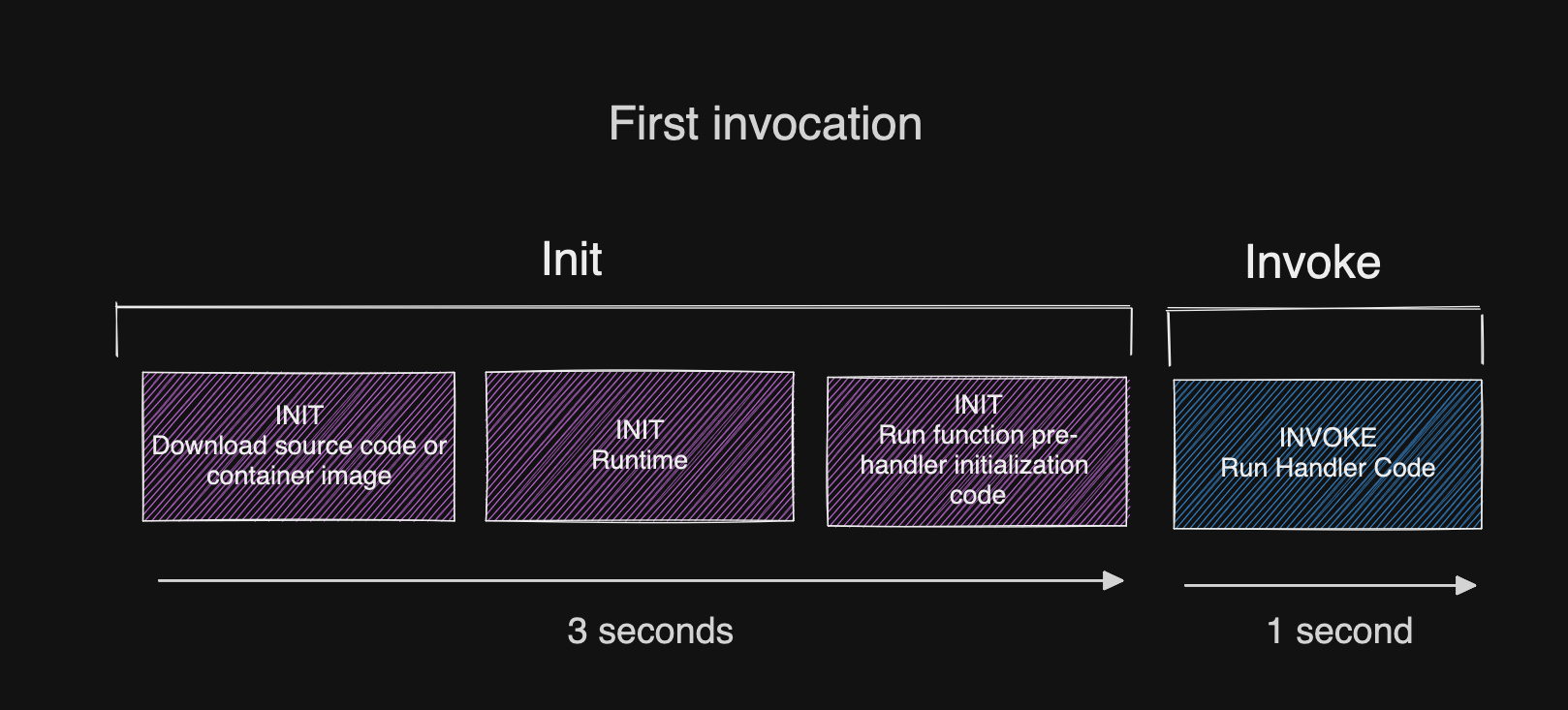
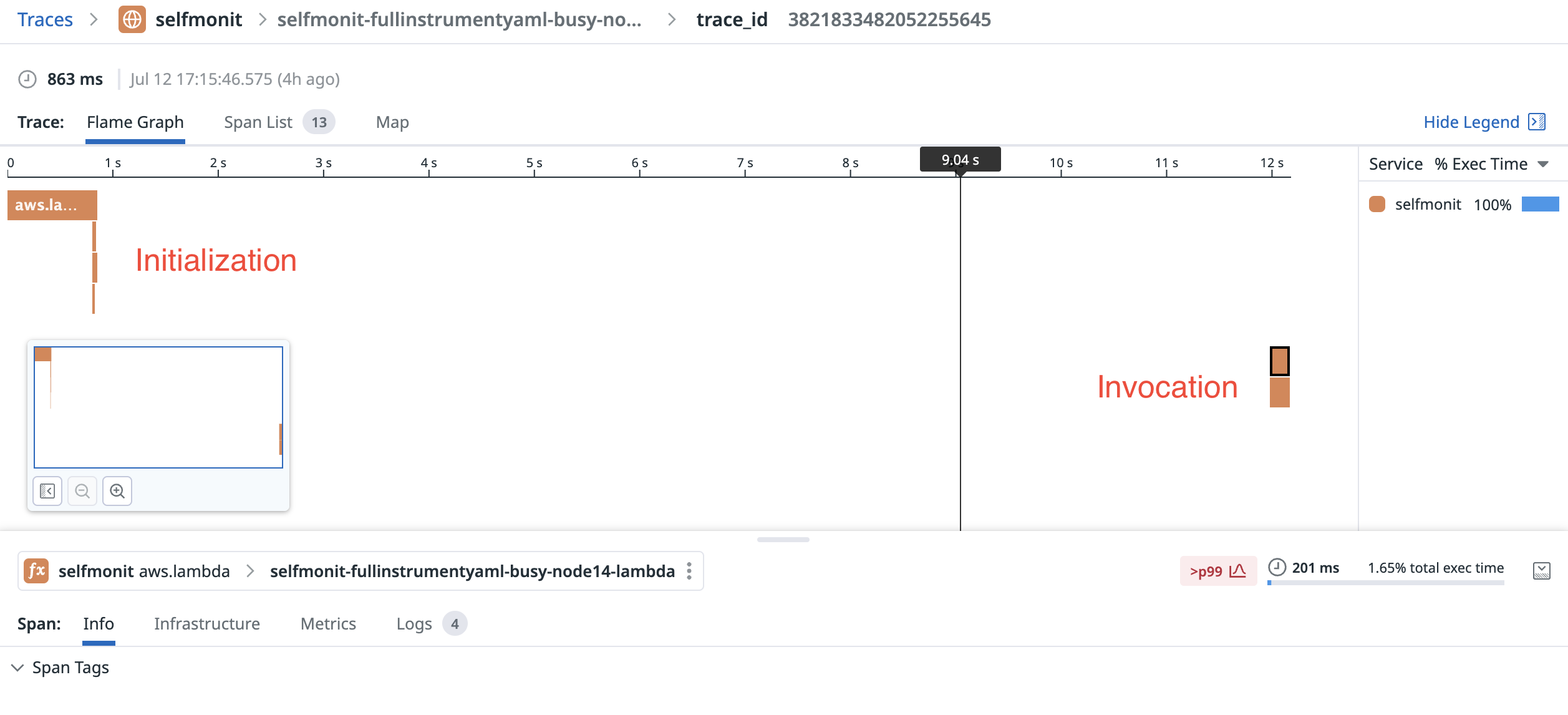
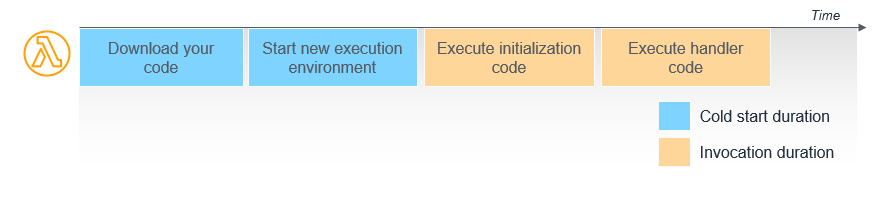
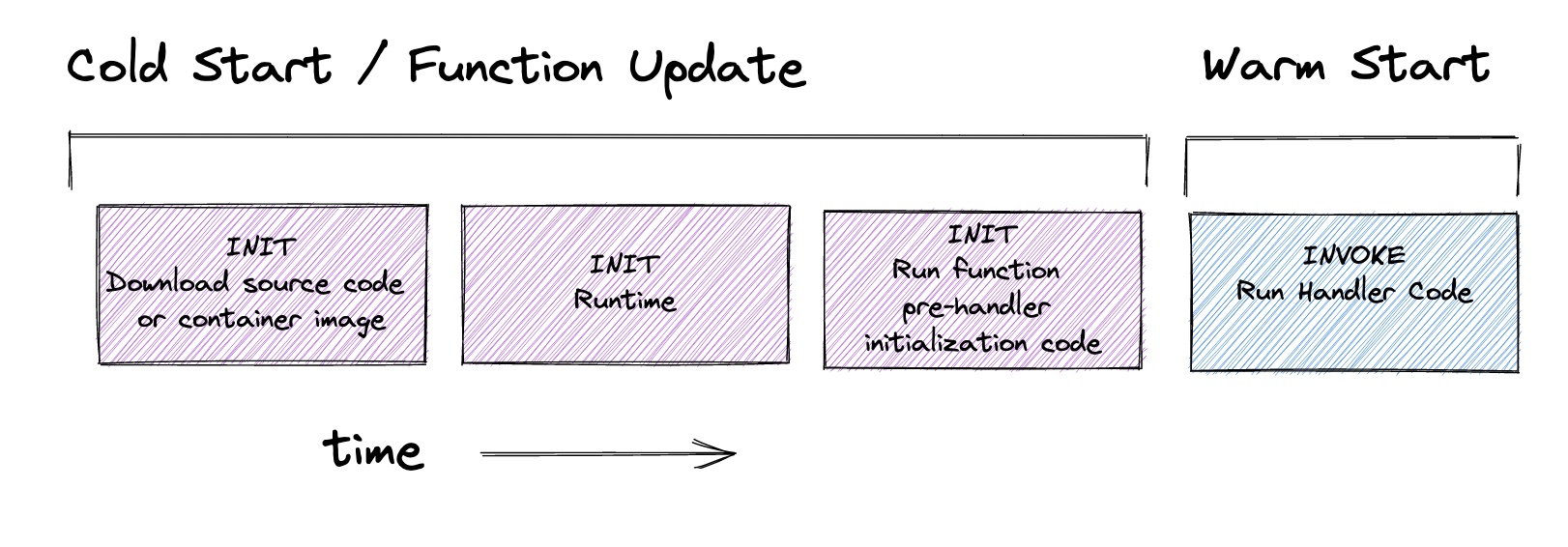
It’s important to note that when you update environment variables, you will trigger a cold start (as long as you’re using the $LATEST function alias). Your function sandbox is automatically shut down permanently. Then when a new request arrives, you will experience a cold start and that sandbox will pull the latest environment variables into scope.
Environment variables are also the best-performing option. Systems Manager Parameter Store, Secrets Manager, Lambda environment variables, and KMS all fundamentally rely on KMS and thus a call to kms:Decrypt at some point.
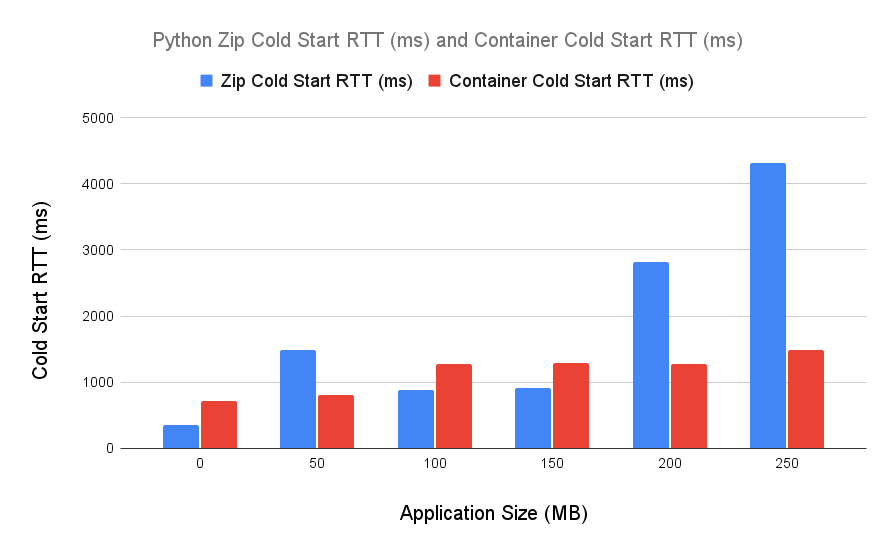
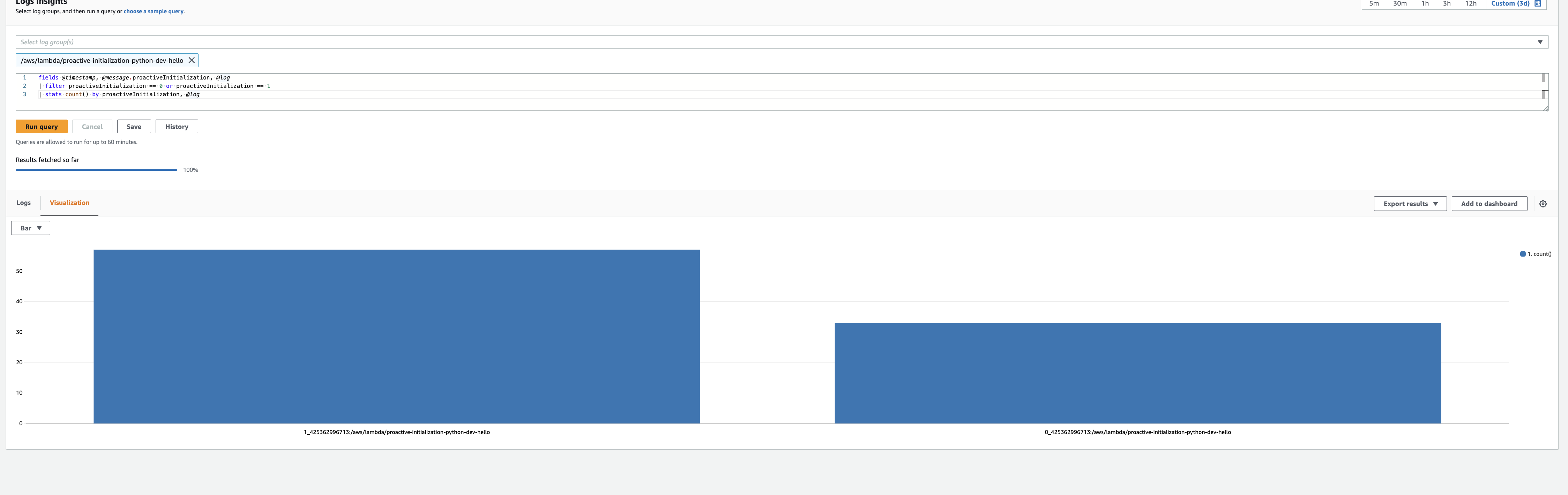
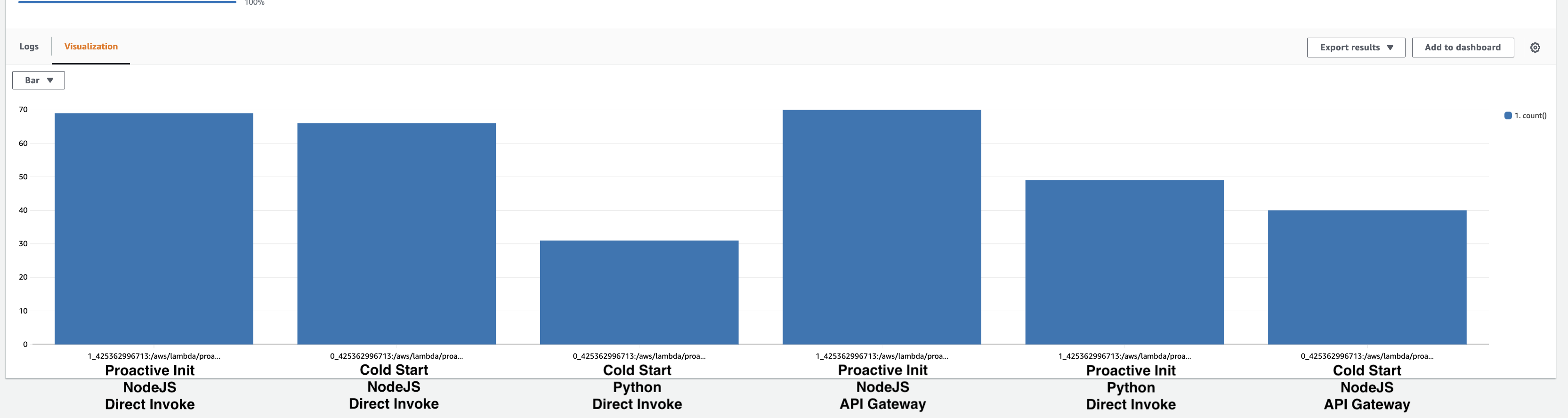
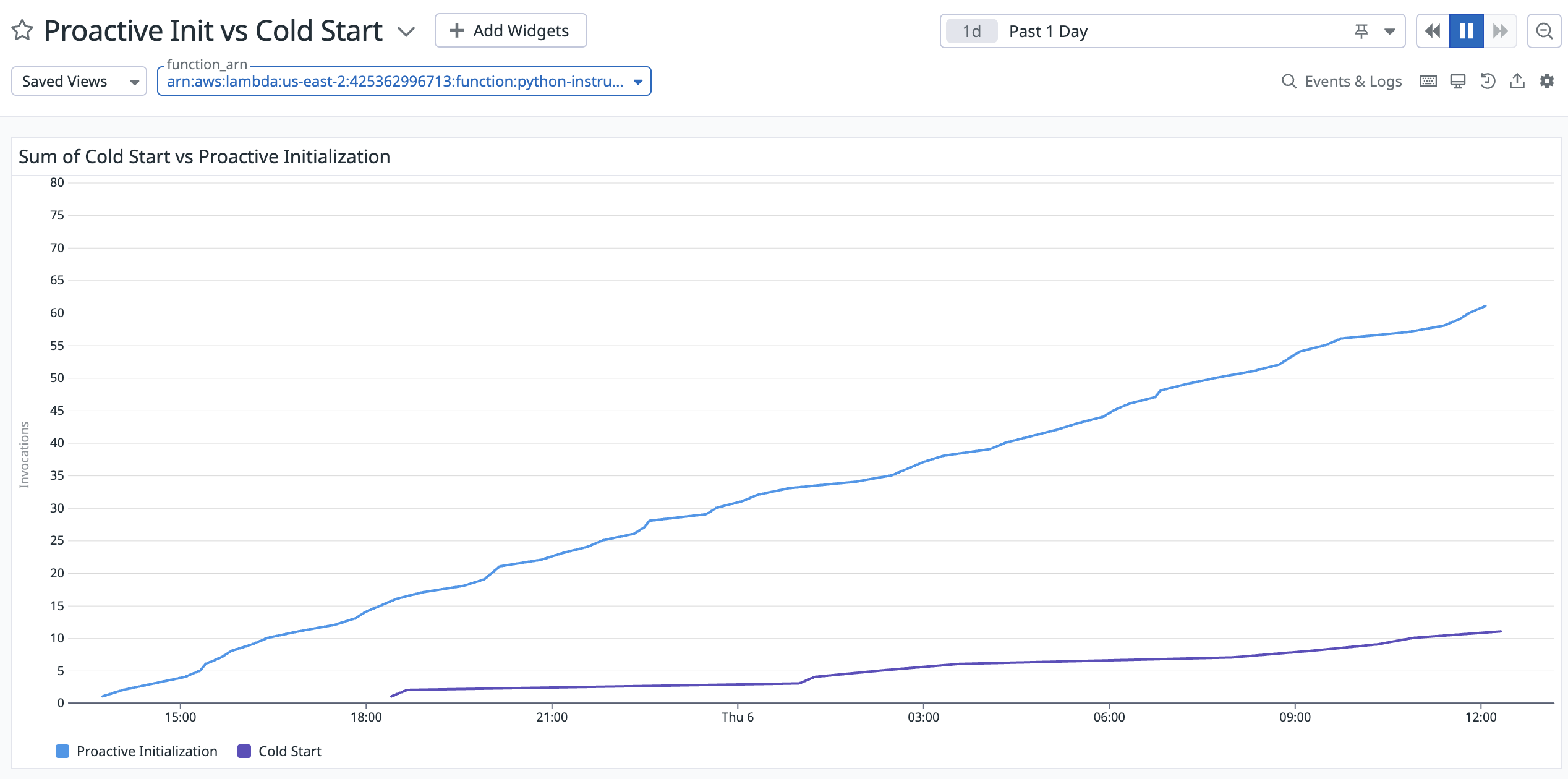
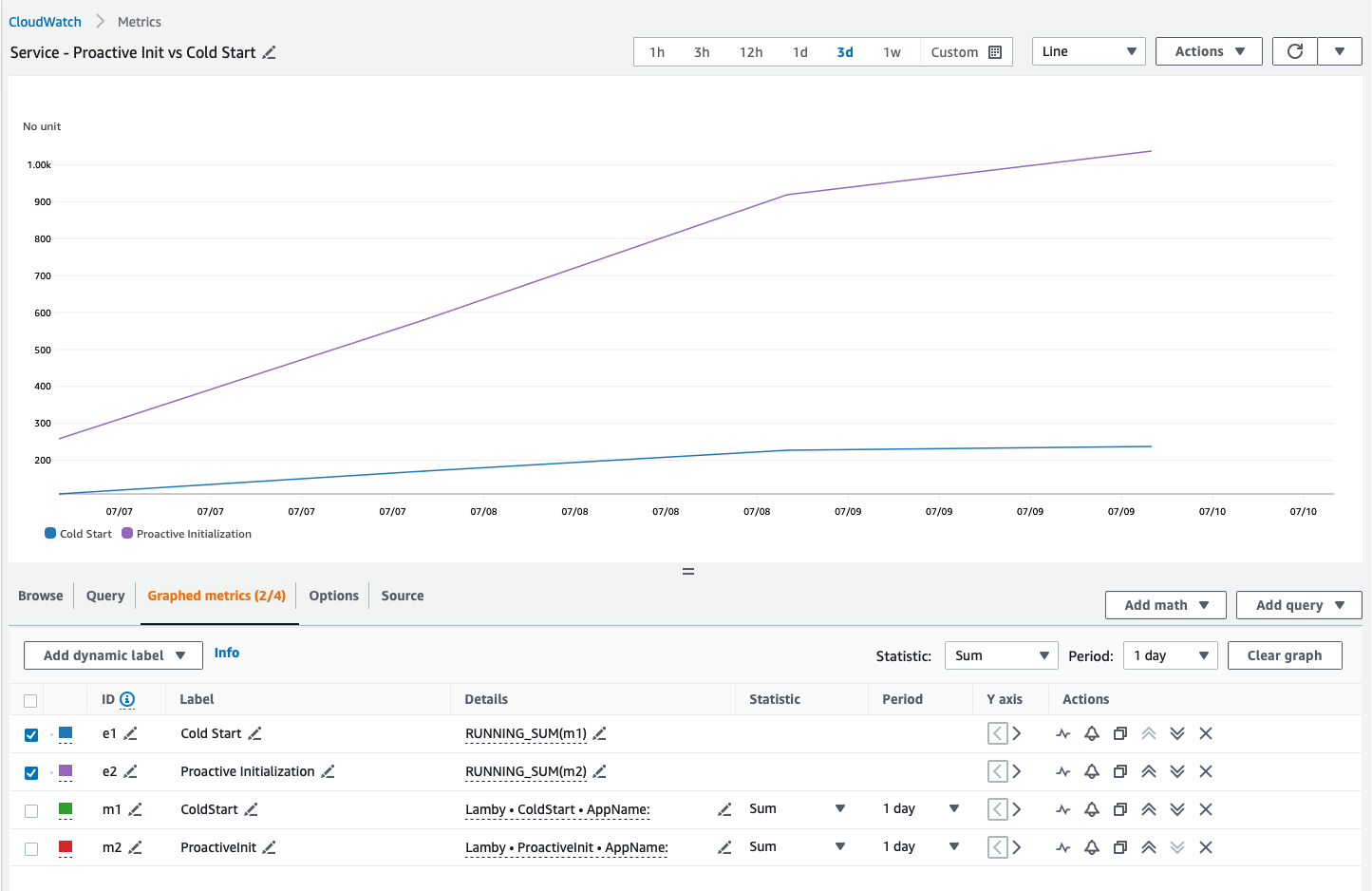
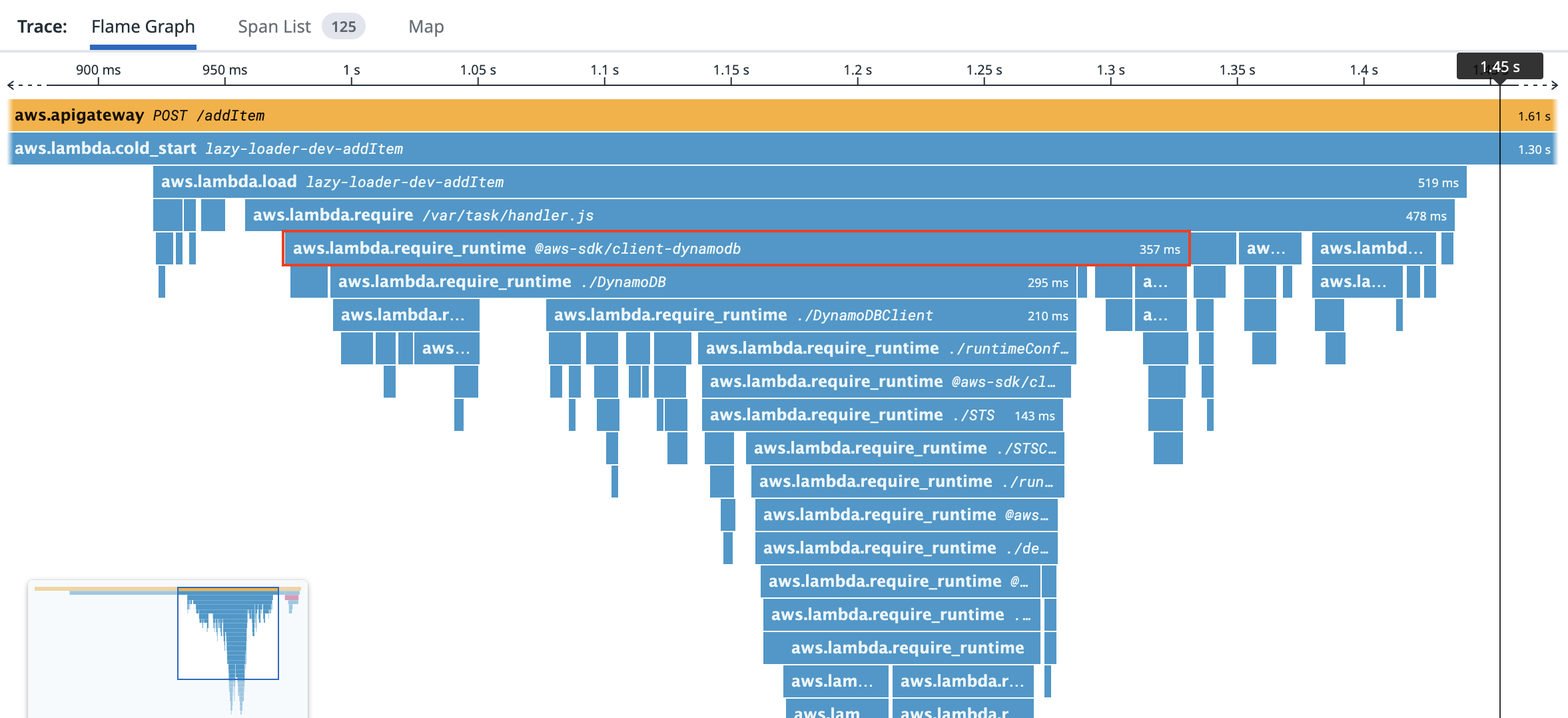
Lambda Function environment variables add around 25ms to your cold start duration, according to an article David Behroozi just wrote. These calls are logged in CloudTrail whenever your function starts.
However, purely storing secrets as environment variables is not the most secure option. Although they are encrypted at rest, environment variables and lambda:GetFunctionConfiguration permissions are treated by Lambda as part of the ReadOnly policy used by AWS internally, auditors, and cloud security SaaS products. This broadens your risk for a vendor or 3rd party auditor becoming compromised and leaking your secrets.
One risk is that you may accidentally leak a secret when sharing your screen while viewing or modifying a Lambda environment variable. It’s unfortunate that AWS automatically decrypts and displays these values in plain text. AWS has no excuse for this, and should absolutely hide environment variable values unless toggled on, which is how Parameter Store and Secrets Manager both work.
Furthermore, CloudFormation treats environment variables as regular parts of a template, so they are available when looking at the full template or historical templates for a given stack. Additionally, AWS does not recommend storing anything secret in an environment variable.
You can improve that somewhat for no (or little) cost using a pattern I lay out further on. Before we get there, you should be familiar with the first-class products AWS offers to store your secrets.
AWS Systems Manager Parameter Store
The title is a mouthful, and the service is equally Byzantine. It includes features for managing nodes, patching systems, handling feature flags, and so much more. Earlier it was called the Simple Systems Manager, however it’s truly anything but simple.
Today we’ll focus only on Lambda and exclusively on the Parameter Store feature which allows us to store a plaintext or secure string either as a simple value or structured item.
You always want to use SecureString for secrets.
Parameter Store offers the choice between Standard and Advanced Parameters. Standard Parameters are free to store, Advanced Parameters incur a $0.05 per month per parameter charge.
Standard parameters are limited to 4KB in size (each), with 10,000 total per region. Advanced Parameters have higher limits of 8KB per item and 100,000 total per region. They come with the bonus of attaching Parameter Policies, which are effectively TTLs for a given parameter.
Standard Parameters are free up to 40 requests per second (for all values stored in Parameter Store). Beyond that, the cost is $0.05 per 10,000 Parameter Store API Interactions. Advanced Parameters are always billed at $0.05/10,000 requests. Fetching each parameter counts as an interaction, so 10 parameters triggers 10 interactions. Parameters are individually versioned, and you can fetch by version or $LATEST.
Historically one major advantage of Secrets Manager over Parameter Store is the ability to share secrets across AWS accounts using a resource-based policy. This is now supported by Parameter Store for Advanced Parameters as well.
Finally, individual Parameter calls are auditable in CloudTrail so you can prove who accessed a Parameter and when.
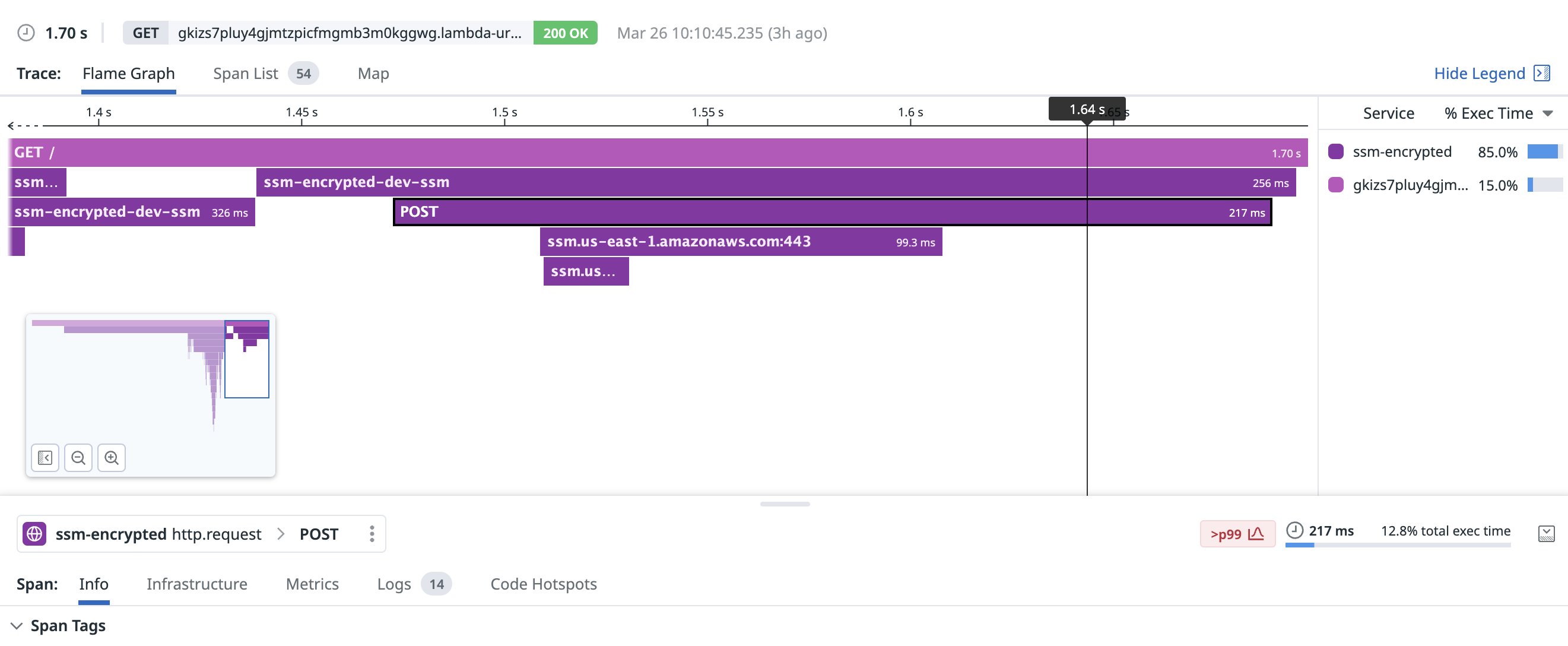
For a new TCP connection, Parameter Store fetched a parameter in around 217ms, including 99ms to set up the connection itself:
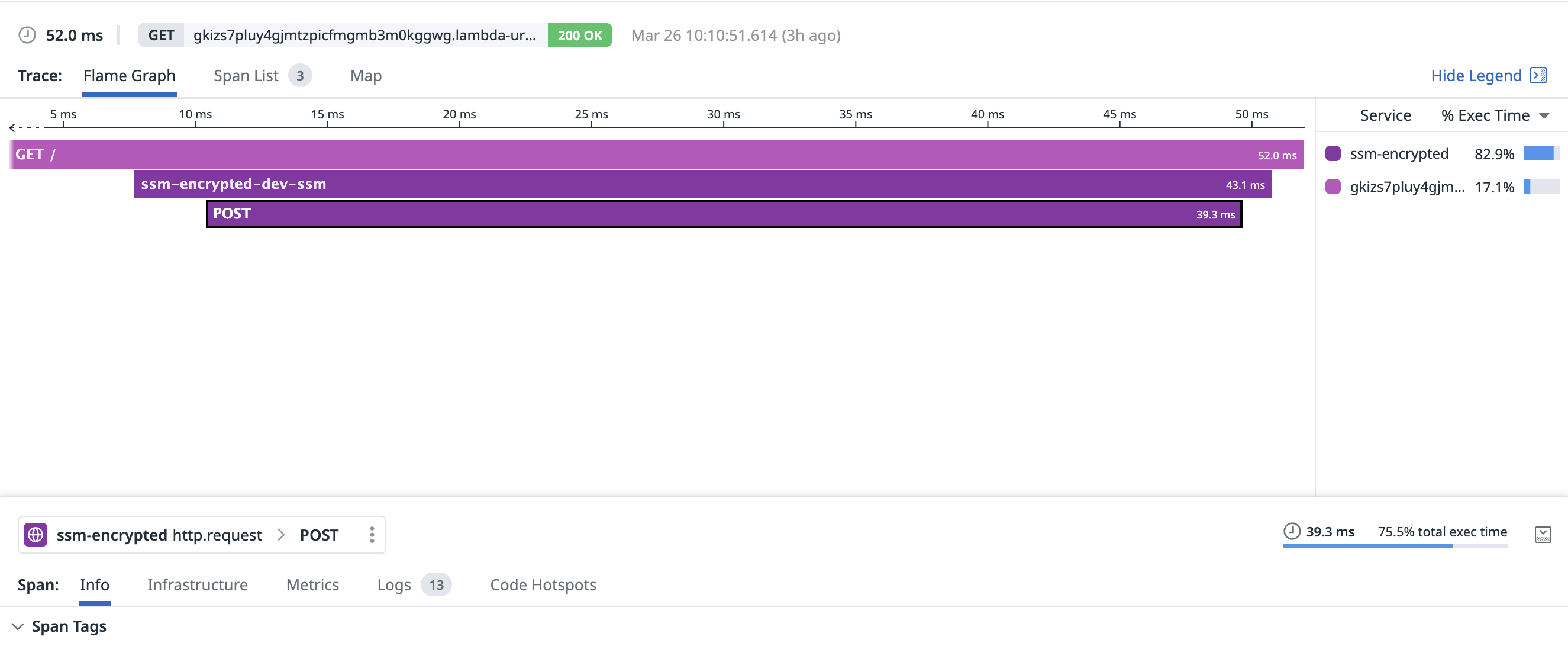
With an existing connection, fetching the parameter took around 39.3ms:
AWS Secrets Manager
Secrets Manager is purpose-built for encrypting and storing secrets for your application. It also has the largest cost at $0.40 per secret per month. This cost is multiplied by the number of regions you choose to replicate each secret to, so this can add up quickly. Fetching a secret costs $0.05 per 10,000 API calls, and there is a free 30-day trial.
The big features you’ll gain over Parameter Store are the ability to automatically replicate secrets across regions, automatically (or manually) rotate secrets. This feature often satisfies requirements for applications subject to regulations like PCI-DSS or HIPAA. If these are must-have features for your application, it makes sense to use Secrets Manager.
Secret values can be up to 65KB in size, which is far larger than environment variables or Parameter Store. Like Parameter Store, calls for GetSecretValue are logged in CloudTrail. The big advantage Secrets have over Parameter Store is the ability to simply rotate or change a secret everywhere it’s used. You can do this on a schedule if you’re in an environment which demands this, or ad-hoc.
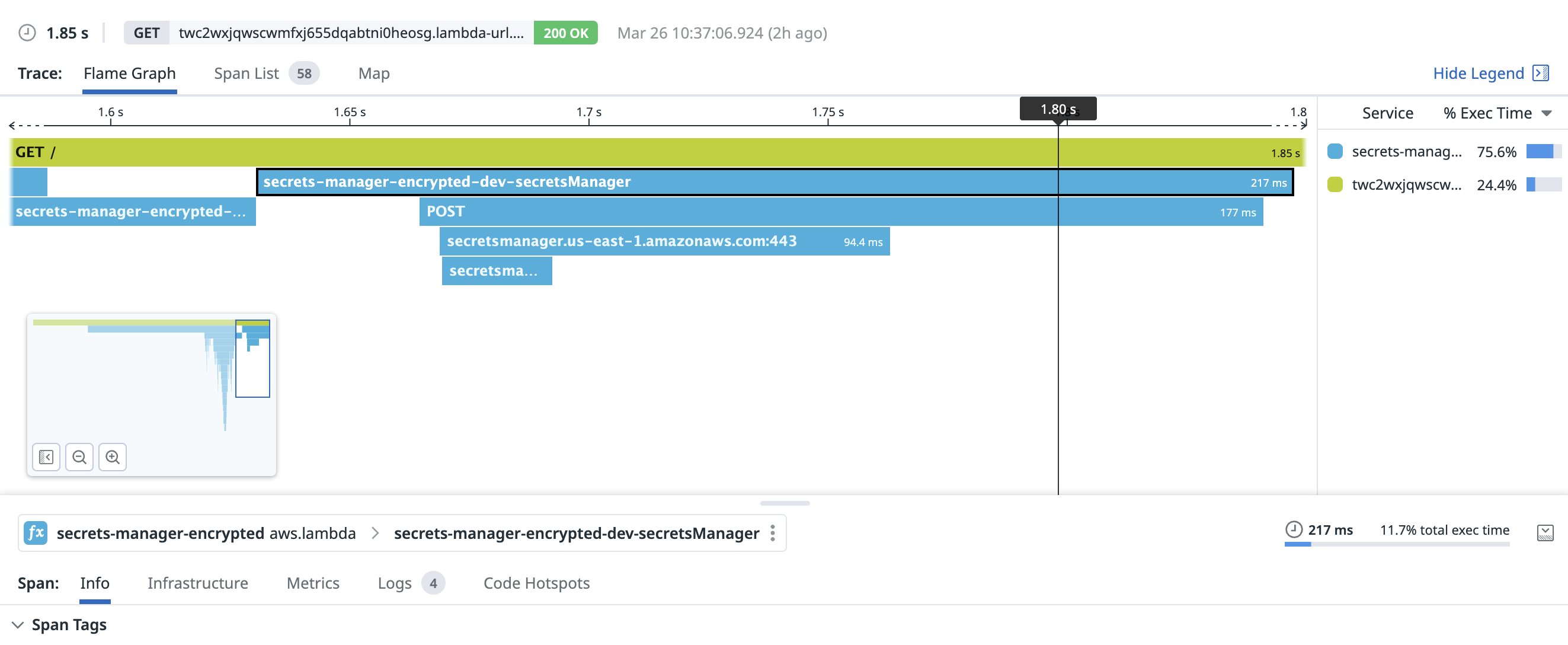
Similar to Parameter Store, it takes Secrets Manager a bit to warm up. 177ms was the duration to create this TCP connection and make the request:
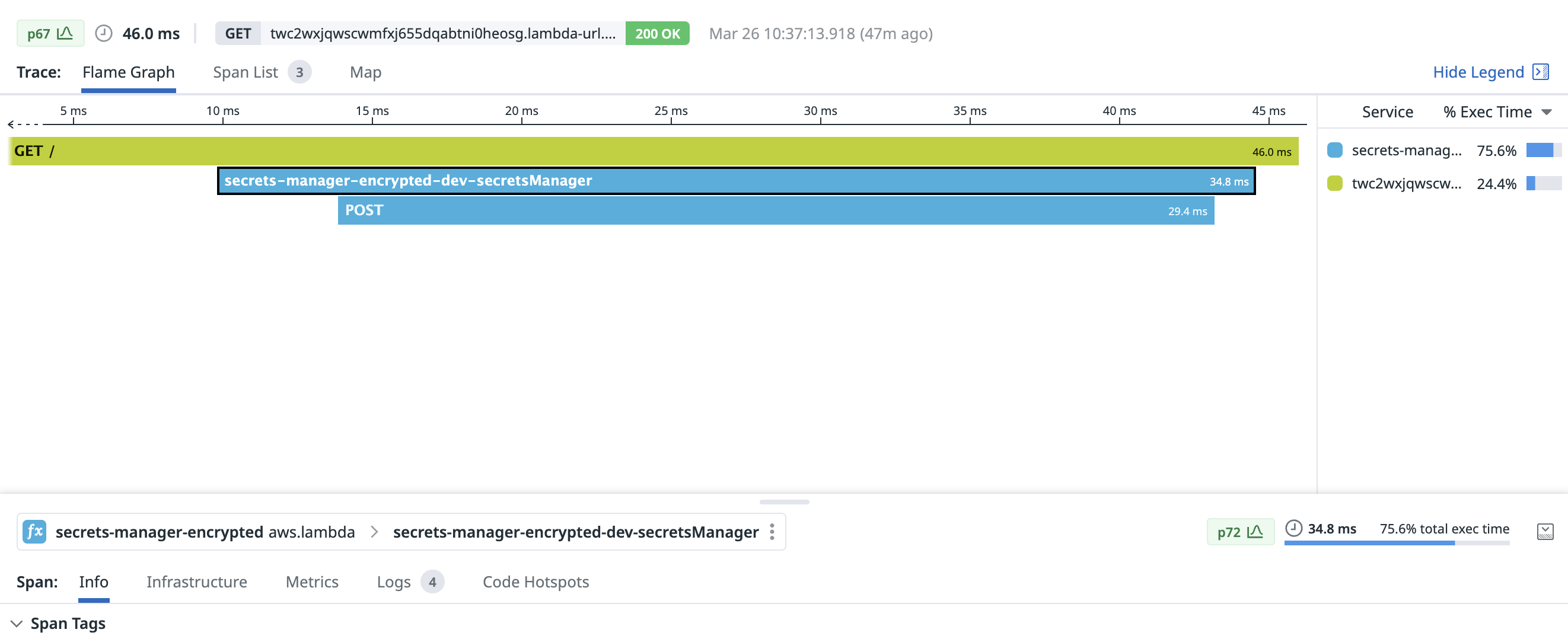
With a warm connection, fetching a secret from Secrets Manager took only 29.4ms:
Key Management Service
AWS Key Management Service (KMS) is the system which underpins all of these other services. If you look carefully at either the documentation or CloudTrail logs, you’ll see KMS!
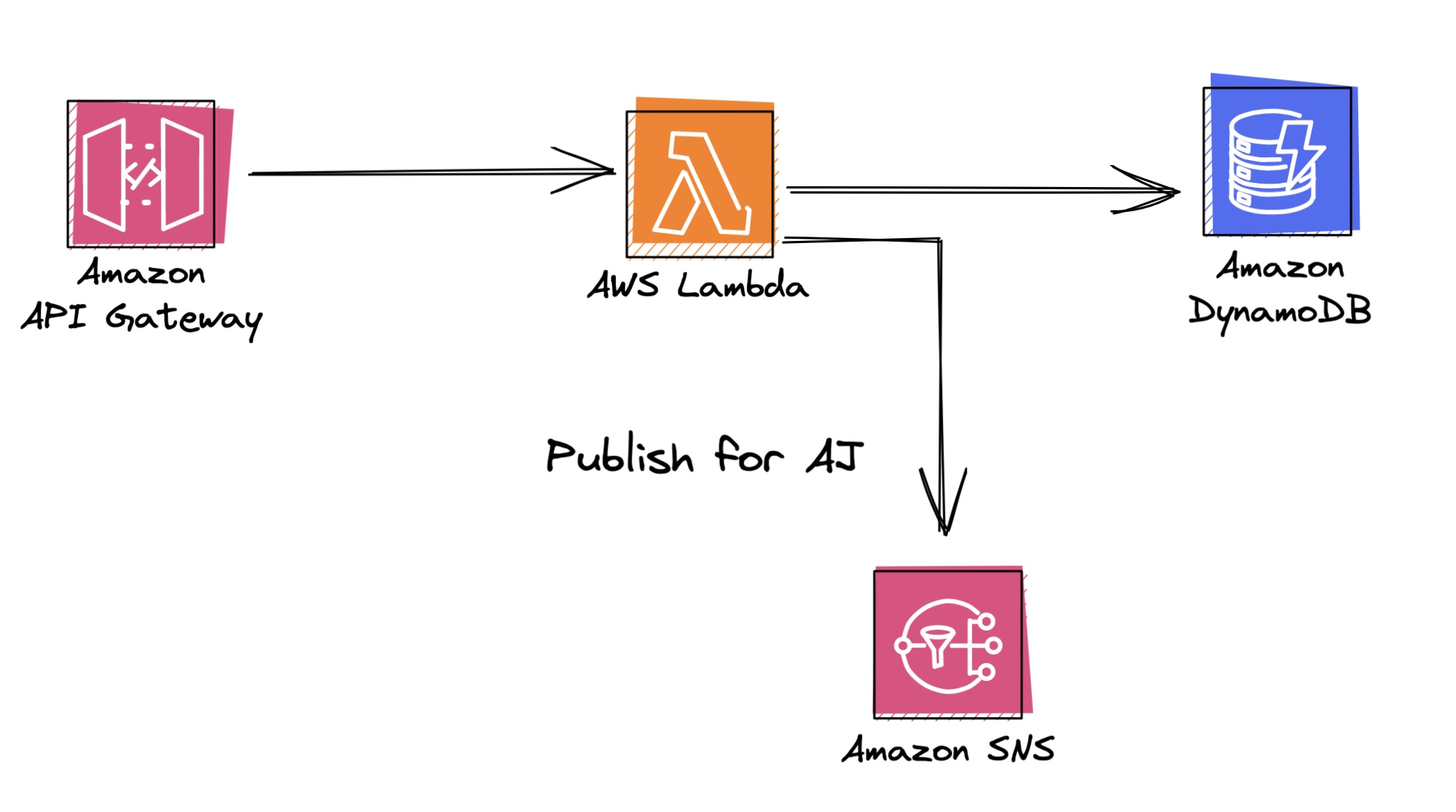
KMS allows us to create an encryption key, securely store it within AWS, and then use IAM to grant access to resource-based policies used by Lambda to decrypt the ciphertext when your function runs. Instead of passing around a reference to a secret, you’ll need to pass your Lambda function the encrypted ciphertext.
Storing and fetching the ciphertext can be implemented many ways, and should generally track the size of the encrypted blob. Small strings can be easily encrypted and stored as environment variables. If you need to share the same secret, you can store the ciphertext in DynamoDB. For large shared secrets, ciphertexts can be stored in S3.
Most often these secrets are decrypted during the initialization phase of a Lambda function. Fun fact, you don’t need to store or pass the ID of the key used to encrypt data. That key ID is encoded right along with the encrypted data in the ciphertext! Simply call kms:Decrypt on the blob, and KMS takes care of the rest. Neat!
KMS bills $1 per key per month. There is no charge for the keys created and used by Parameter Store, Secrets Manager, or AWS Lambda. You’re also charged $0.03 per 10,000 requests to kms:Decrypt (or other API actions). These calls are individually auditable in CloudTrail.
You’ll have to implement rotation yourself, but if you store ciphertexts in DynamoDB, this can be relatively straightforward and cheaper than either Parameter Store or Secrets Manager, especially if you want to distribute a secret across multiple regions.
I see KMS used most frequently to encrypt slowly changing items like certificates, .PEM files, or to securely store signing keys.
Decrypting one small (~200b) ciphertext with KMS is notably faster than Parameter Store or Secrets Manager. This request took 64.4ms, including creating the TCP connection:
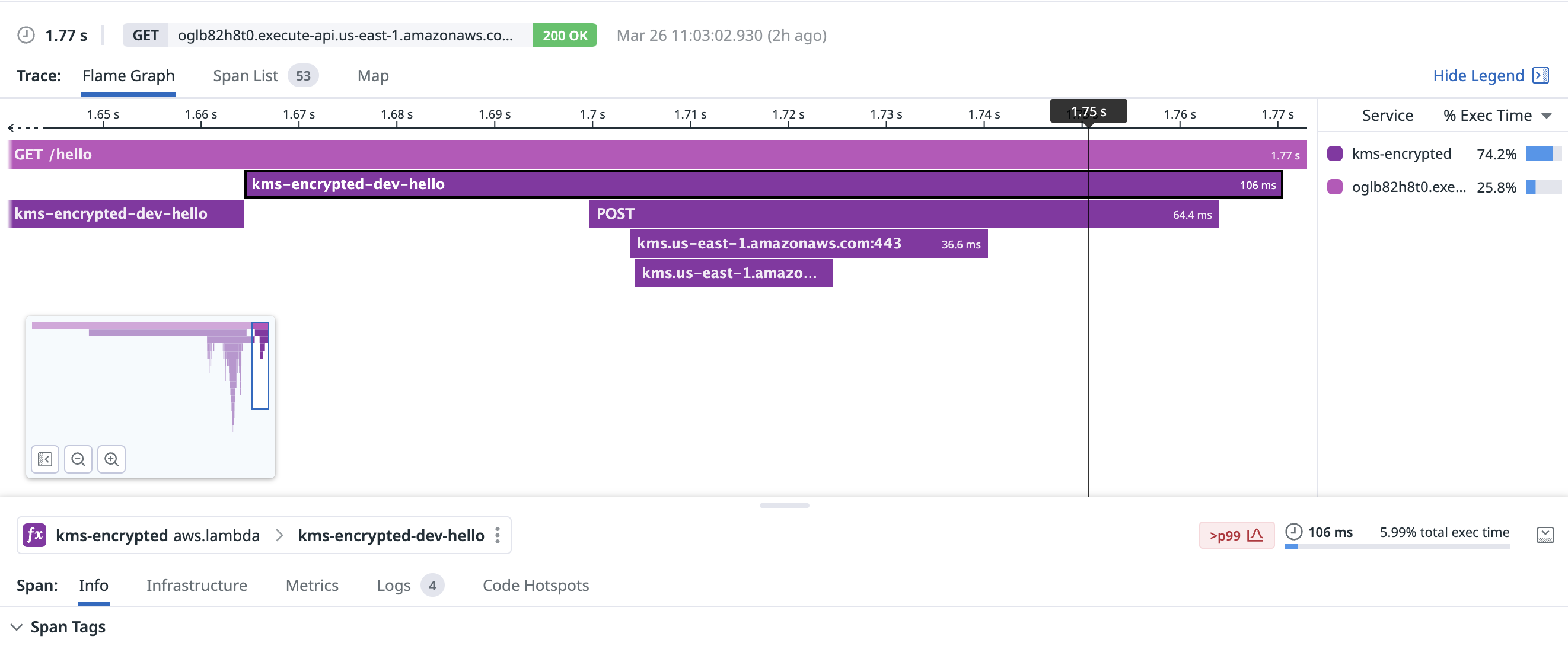
With a warm connection, KMS decrypted my secret in a blistering 6.45ms:
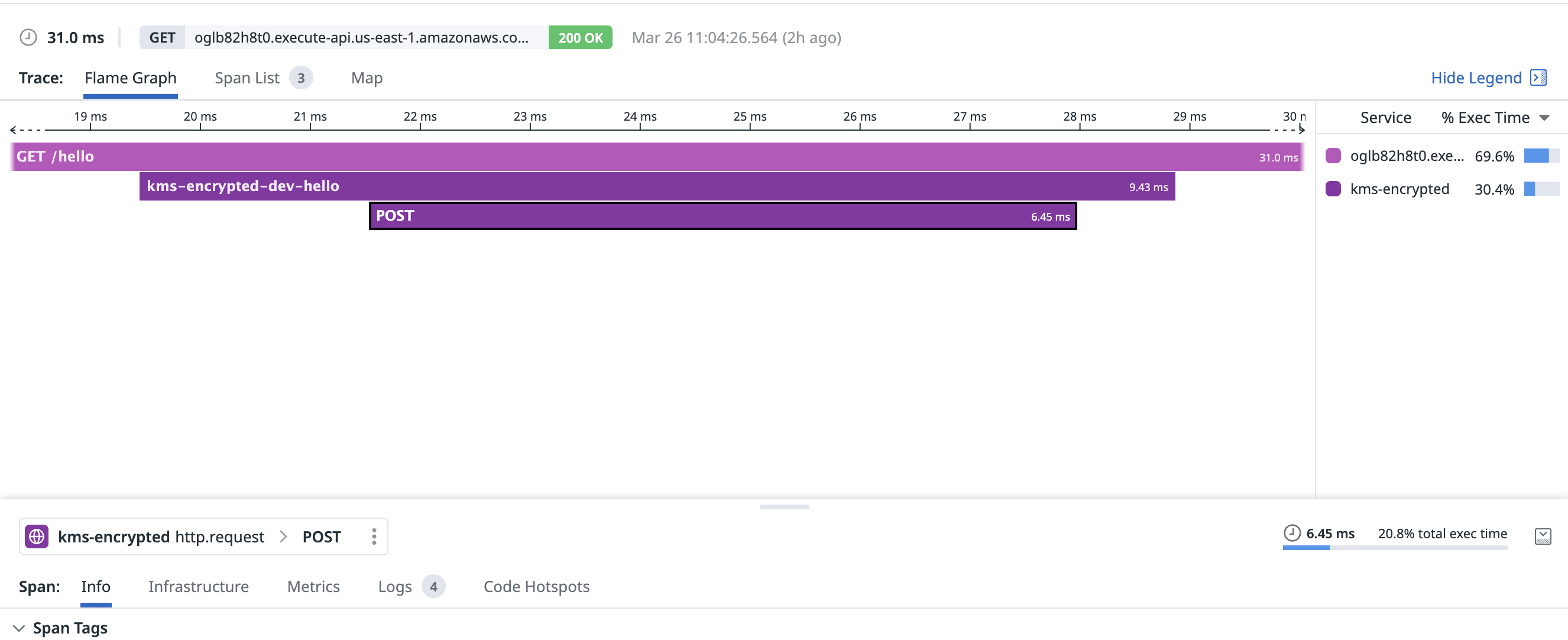
Presumably a big advantage here is that my ciphertext was already present in Lambda (as an environment variable) and didn’t need to be fetched from a remote datastore call. KMS merely needed to decrypt the ciphertext and return!
AWS Parameter and Secrets Lambda Extension
To more easily use either Parameter Store or Secrets Manager in Lambda, AWS has published a Lambda extension which handles API calls to the underlying services for you, along with caching and refreshing secrets. You can tune these parameters to your liking as well.
Your function interacts with this extension via a lightweight API running on localhost. It’s reasonably well designed, although I find it a bit clumsy overall. This really feels like the type of feature Lambda should implement themselves, and then magically make secrets appear in your function runtime. In contrast, ECS has this behavior built in and I find the experience far superior compared to Lambda.
Furthermore, this extension isn’t open source. Because extensions are indistinguishable from your own function code, it leaves a bit of a foul taste in my mouth that I’m completely blessing a random extension with carte-blanche access to both my function code and secrets.
I’m of the firm opinion that we as users shouldn’t seriously consider any Lambda Extension unless the code is open source (and can be built/published to my own account if I choose). If AWS changes this behavior, I’ll happily update the post.
For these reasons, I prefer interacting with the Parameter Store or Secrets Manager APIs instead, using the aws-sdk. The (excellent) AWS Lambda PowerTools project also supports fetching parameters from multiple sources and is absolutely worth considering.
Now let’s consider three example secrets. We’ll look at the attack vectors, the blast radius for a leak/compromise, and identify the best cost/benefit solution for each.
Patterns and Practices
Safely securing environment variables
Given that AWS Lambda environment variables are encrypted at rest - the biggest issue storing sensitive data in environment variables isn’t Lambda itself - it’s the AWS Console and CloudFormation (and your CI pipeline)! When your stack is created or updated, those environment variables are plaintext values in the CloudFormation stack template. Templates are also stored and retrievable in the CloudFormation UI, as well as in the AWS Lambda console.
Unfortunately you’re not able to use dynamic references to pass a reference to your secret to CloudFormation, because they aren’t yet supported by Lambda environment variables. You should complain about this to your AWS TAM.
The downside is that your secrets are still viewable in the Lambda Console via lambda:GetFunctionConfiguration, and if you update your secret in Parameter Store, it won’t be updated in Lambda until you redeploy your functions.
Envelope Encryption
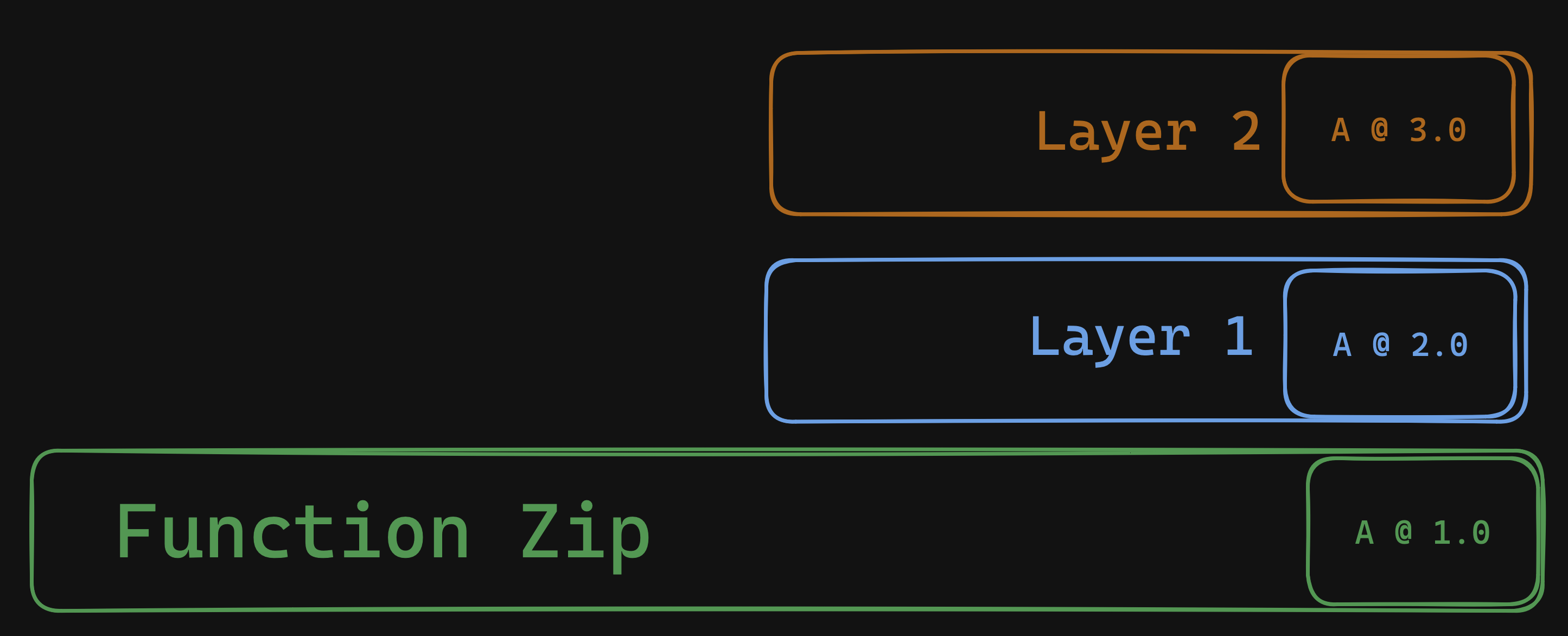
Consider a case where you may have ~100kb of secrets to store. A handful of signing keys, a couple tokens, maybe an mTLS certificate. Here’s where you can use a technique called envelope encryption to secure your data.
- Create a KMS key
- Generate 256-bit AES key for each customer, application, or secrets payload
- Encrypt all of your secrets with the AES key. This is the “envelope”
- Include the encrypted secrets in your function zip.
- Finally, encrypt the AES key with your KMS key and pass the encrypted key to your function in an environment variable.
You’ve just encrypted an envelope, and passed the encrypted key to your Lambda Function securely! This also helps save money on KMS keys, as you can re-use one KMS key for multiple AES keys. This pattern is also useful if you need to secure keys for customers in a multi-tenant environment, but laying that out is beyond the scope of this post.
Sensitive Data Exercise
We’ve covered the fundamental building blocks for securing sensitive information within AWS and using it within Lambda. We’ve also composed a few patterns you can use to reduce costs or handle specific use cases.
Now, let’s consider 4 common secrets used in Lambda and think about how best to secure them.
Telemetry API Key
First up is a telemetry API key. Consider an ELK stack, or any provider you prefer. These keys are free to create, so it’s best to create one key per application to limit blast radius and, as a bonus - better track costs. Telemetry keys are also usually write-only. Leaking this key can only cause an attacker to send additional data to the API.
With this in mind, environment variables are likely a good enough option here. They have minimal performance overhead, no cost, and minimal blast radius.
Keys can be easily created for exactly one Lambda function, or CloudFormation stack. If someone peers over your shoulder at a coffee shop, or inadvertently leaks the environment variable - it’s simple to change with a few clicks and a re-deploy.
You can also use dynamic references and limit the read permissions for console users or 3rd party roles to further prevent access.
Using a SecureString with Parameter Store would also be a good option as it would likely be free - especially if your application doesn’t have any users.
In this case, the blast-radius is small, the rotation complexity is easy, and a key encrypted at rest is likely more than suitable for our use case.
Database Username and Password
Your RDBMs may only allow one username and password string, to be shared across all applications - or maybe you just need to share a secret for the sake of simplicity. If you’re not using a stateful connection pooler (like pgbouncer), you may need to share this secret with all your functions.
Here’s where Parameter Store is probably also a great fit. If you ever have to change it, your functions can reference an unversioned Parameter and get the latest key. For one key, it’s pretty affordable. However this math changes if you have a larger bundle of secrets, which exceed the 4KB or 8KB size limits of Parameter Store.
GitHub Application Private Key
For our second example, consider building and deploying a GitHub Application. Authenticating as a GitHub Application is not quite as simple as a 128bit UUID.
Instead, you must download and save an application key in PEM format. These keys can be a bit large, around ~2KB which may push you close to the 4KB environment variable limit.
You can create multiple keys for the same application at no cost, so deploying one key per stack is still tenable.
If the key were to be leaked, someone could conceivably authenticate as your application and access ANY of the repositories your application is installed into (with whatever permissions your application is configured to use). This is risky!
In this case, you’d probably want to use something like Parameter Store if you choose to create multiple keys and rotate them yourself. You’ll help avert the size limit for Lambda environment variables, but it won’t be too costly.
If you’re dealing with a larger key but don’t want to eat the cost of Secrets Manager, KMS or DynamoDB can make sense as well.
I’d be remiss if I didn’t mention that like Lambda environment variables, DynamoDB records are also encrypted at rest, optionally with your own consumer-managed key. I assume this is mostly at the hardware (disk) level, so data in memory may not be encrypted. But generally if you’re also concerned with someone peeking over your shoulder as you browse DynamoDB items in the AWS console, you could also encrypt them with your own key.
PCI-DSS or HIPAA credential rotation
If you’re in a regulated environment with mandated credential rotation, Secrets Manager makes this so easy. As this post has mentioned several times, it’s certainly possible to build this yourself. However - it’s often worth the cost of $0.40 per secret to have the peace of mind that Secrets Manager will automatically rotate your secrets on a regular cadence. Your auditor will thank you as well.
Wrapping up
My hot take after writing this guide is that Lambda environment variables are generally fine for a one-off API key with a small blast radius. They’re fast, free, and easy to use.
For secrets with larger blast radii, use SecureStrings from Parameter Store. If you’re working in a regulated environment or you’d like to regularly rotate a secret, it’s probably easiest to use Secrets Manager.
Reach for KMS and another storage mechanism if your use case doesn’t quite fit into these boxes, or if doing so would be prohibitively expensive.
Ultimately security is a balancing act. I realize best practices are all about limiting risks at every turn, but it still feels wrong to crow about environment variables when so many developers run around with Administrator IAM roles (and can easily read any secret anyway).
At the same time, AWS should do more to restrict the values of environment variables to a permission more restricted than lambda:getFunctionConfiguration.
This post would not exist without David Behroozi challenging me to finish it, and helping out with his CloudTrail digging. You should follow him on twitter. Thanks, David!
Nick Frichette, Alex DeBrie, and Aidan Steele also helped review this, thanks friends!
If you like this type of content please subscribe to my blog or follow me on twitter and send me any questions or comments. You can also ask me questions directly if I’m streaming on Twitch or YouTube.
]]>






{kind=link}