BASE Jumps & Backups - how I use Synology and AWS to store my data
Erasure coding and multi-tier backups can help you store your data safely and cheaply. Here's how I use a Synology DiskStation and AWS Glacier to store my BASE jumping videos, and my opinions on both after a bit of use.
July 8, 2024
If you mostly know me because of this blog or my cloud talks, it may surprise you to learn that I’m also an avid parachutist. I’ve been skydiving since 2010 and BASE jumping since 2012, and have more than 1200 combined jumps all over the world. It’s a neat hobby! Contrary to popular belief, it’s not as dangerous as you might think.

Starting in 2010 also means I’m a child of the GoPro era. This was the beginning of YouTube. Like so many others I was inspired by videos of people soaring down cliffs. So against the guidance of literally everyone, I strapped a GoPro to my head and zipped up a wingsuit as soon as I possibly could. Thankfully I managed to develop into a reasonably competent BASE jumper and enjoyed about 10 years of frequent BASE trips, new experiences, and of course several thousand video files.
The fear of losing these files always burned in the back of my mind. I backed everything up to an external HDD, but had no other copies of the data. In case it’s not clear this is a bad thing. Typically, you’d want to have a 3-2-1 backup pattern with an original data set, an on-site backup, and an off-site backup. Since this data isn’t “production” data, I mostly need the original and an off-site backup.
The video files pile up
At the same time, I’ve also been spending more time streaming on twitch and youtube. It’s been fun to poke around serverless platforms, ship toy applications on the weekend, and learn new languages with a small audience. Recently I’d written a few simple benchmarking scripts collecting cold start metrics from AWS Lambda as well as Vercel. I wanted to host these scripts on my local network to simulate what a “real” user may experience, so I knew I’d need a solution which primarily acts as a network attached storage device, but also has a bit of compute available to run my projects. Nothing too crazy, but a unix-like environment would be ideal.
Finally in May, I asked twitter about their recommendations and received a lot of comments. Virtually everyone recommended Synology NAS systems, or had an insane homelab, like my colleague Nick Frichette.
Synology DiskStation
I was introduced to the kind folks at Synology who offered to ship me their DS923+, a couple drives, and the 10GbE upgraded NIC!

After everything arrived, I fired up my live stream and got to work. You can view the whole setup process from start to finish here, but I’ll run you through my major choices.
Synology provided 2x 4tb HDDs, which I opted to store in a fully-redundant setup. This left me around 3.6TB of storage after opting for the Hybrid RAID setup. I chose hybrid raid because I plan to expand the storage further with additional drives, and like the flexibility to mix and match drive size within the same pool.
Setting up the drive pool was a breeze, and after I plugged in the correct network cable, I had things up and running quite easily. I copied my entire external hard drive of archived BASE jumping footage using usb3, but opted to mount the NAS as an SMB to copy archives of my live streams to the NAS over the 10GbE line. This seemed to run as fast as the disks would write!
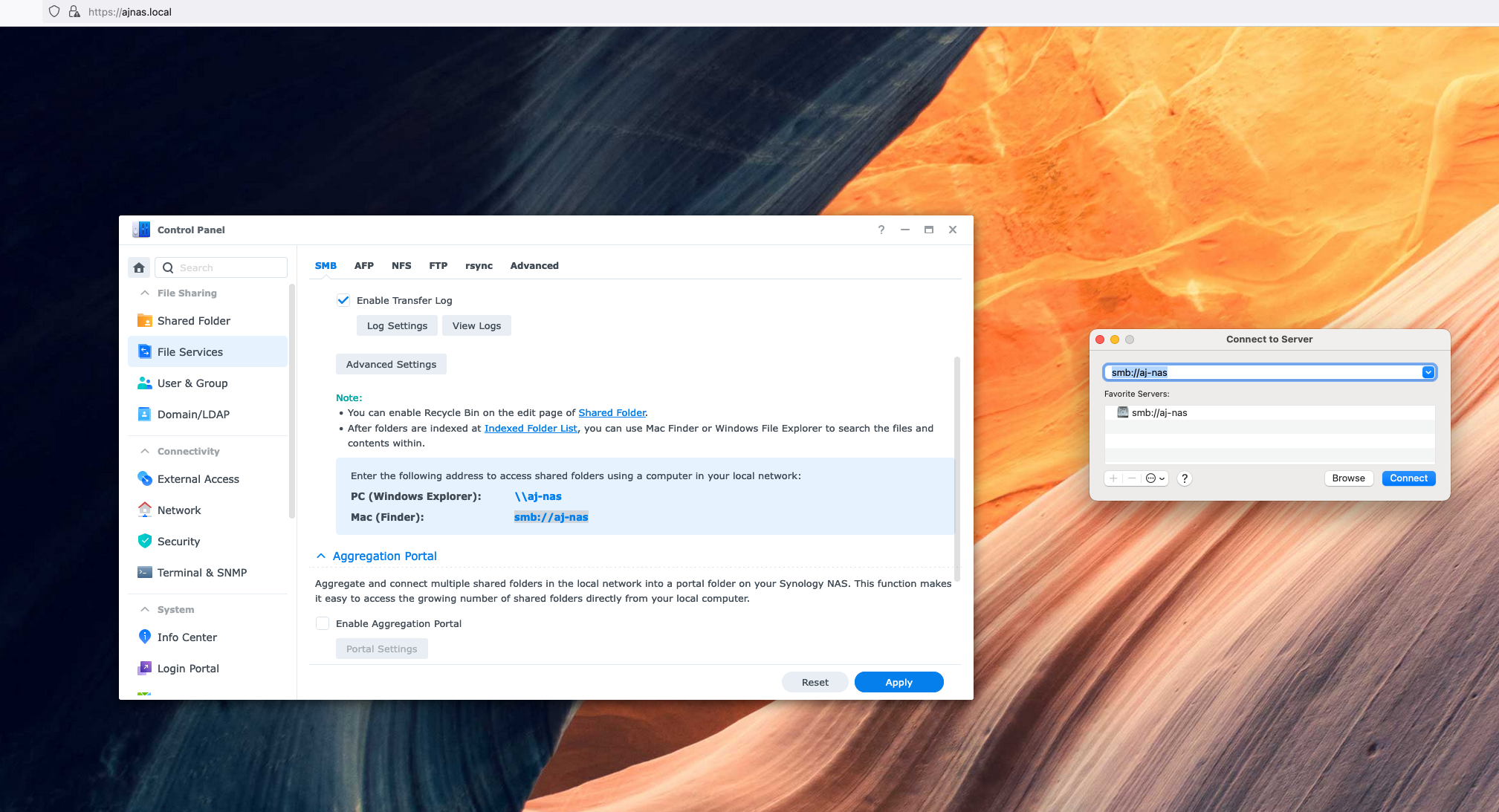
Backing up to the cloud
Within a few hours, I had the entire system unboxed, running and had made 2 full copies of my treasured BASE jumping memories! RAID is great, but it still leaves me with a single point of failure. To prevent this, I knew I’d need to back up this data somewhere else entirely. For this, I chose AWS.
AWS has a dizzying number of storage options, but after some careful thought I realized my choice boiled down to S3 (and the infrequent access tier), and Glacier. Both are arbitrary blob-storage systems, but the main difference is that S3 is geared toward arbitrary, ond-demand file access, whereas Glacier is meant to store archival data which may be retrieved only after creating a retrieval request and waiting a few hours for it to be ready. Both services have multiple storage tiers, but at their slowest/coldest option - Glacier Deep Archive is $0.00099/GB, while S3 Infrequent Access is $0.0125/GB.
Because I already have local copies of my data, if I wanted to watch some videos or edit a new one, I wouldn’t need to use my cloud backup. This meant that Glacier was the right choice for my use case.
Luckily, Synology provides an out-of-the box package for Glacier support. Setting it up was pretty easy, my one complaint here is that the Glacier package on Synology could be a bit more user-friendly in terms of setting up the IAM policy. To start I ended up granting pretty broad Glacier access via IAM. I’m not too worried though. I only leaked the key 5-6 times live on stream! (and rotated it, of course).
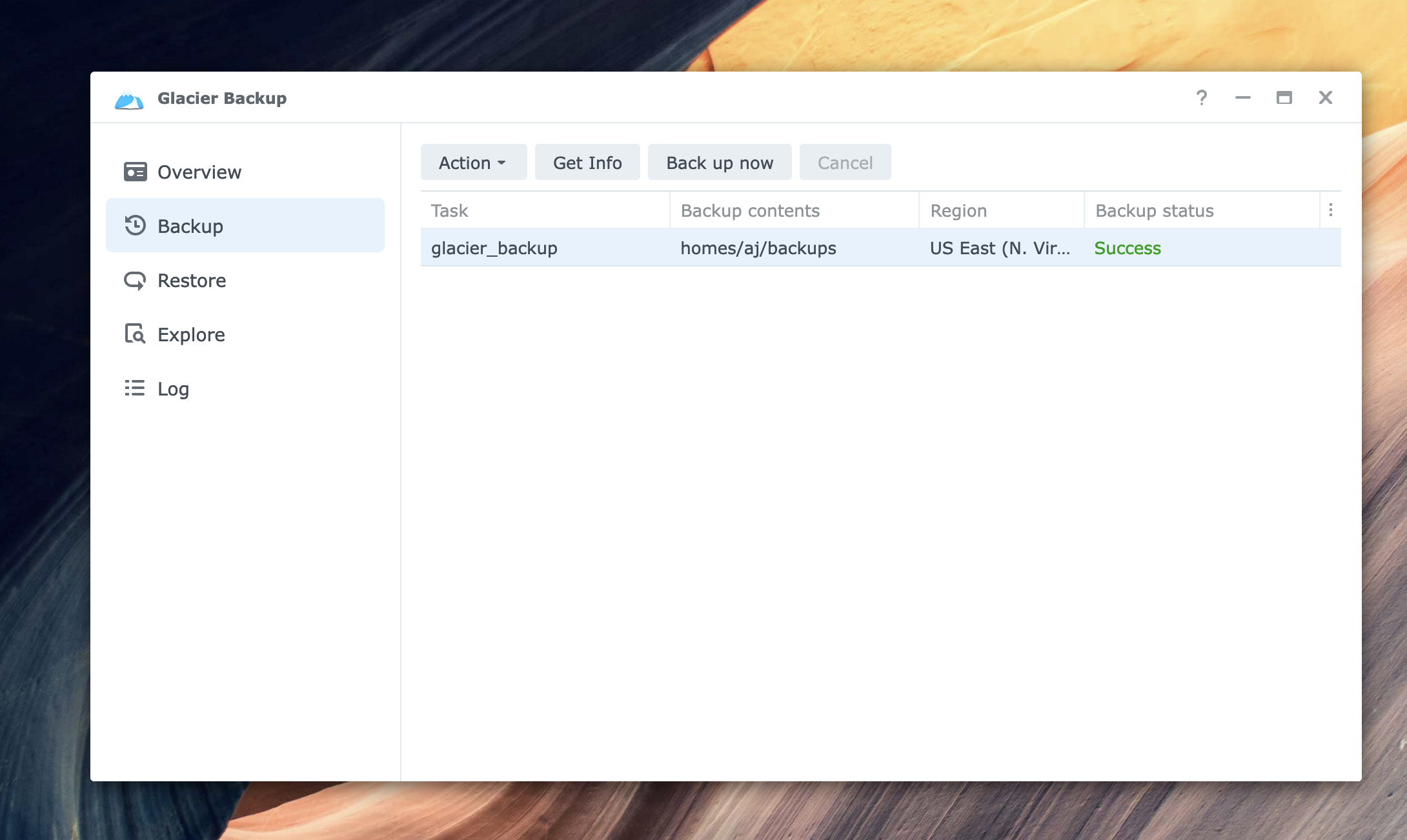
After the backup finished, I consulted CloudTrail to get the specific permissions required. You’ll notice that two archives are created, with one specifically called a mapping archive. I suspect this holds metadata about the backup itself.
At any rate, you can skip this step because I’ve done it for you. Here is the full IAM policy for the Synology Glacier backup package:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"glacier:GetJobOutput",
"glacier:InitiateJob",
"glacier:UploadArchive",
"glacier:ListVaults",
"glacier:DeleteArchive",
"glacier:UploadMultipartPart",
"glacier:CompleteMultipartUpload",
"glacier:InitiateMultipartUpload"
],
"Resource": "*"
}
]
}
You can further limit the two resources to arn:aws:glacier:us-west-2:123456789012:vaults/your-vault-name and arn:aws:glacier:us-west-2:123456789012:vaults/your-vault-name_mapping if you want to be more specific, but I don’t believe you can specify the vault name so you’ll need to use a wildcard to start.
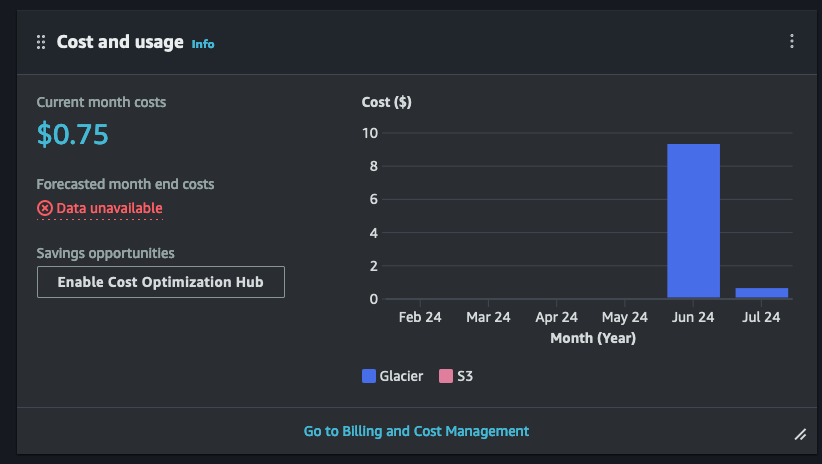
After backing up everything, the costs rolled in. It cost me around $9 to initially back up the data, and will be about $4/month to store it.
I want to take a minute to cover Erasure Coding and why it helps make the web work so well. Building reliable systems means having fault-tolerant systems. For data systems, this means ensuring that the inevitable failing hard drive won’t lead to data loss. But it’s both inefficient and risky to have multiple complete backups of data around. A drive could be stolen or lost in a move, leading to data leaking. And maintaining these complete copies is expensive.
How Erasure Coding works
Enter Erasure Coding. Erasure coding allows us to divide a piece of data like my video files into N slices (or shards in distributed systems parlance). Then instead of backing up each shard (thus increasing the backup size by 2x or 3x), we can transform each shard of N into a slice of data with size 1/K using an encoding function. Now, the original file can be recomposed to N with N-K shards!
For a [3, 2] code, this means we can fetch 2 slices from any of the 3 to full retrieve our data. This is helps improve the tail latency performance of distributed systems, as we can make 3 requests across each of the 3 nodes, but only need 2 to succeed to get the data back.
This example is dramatically simplified, to learn more I’d suggest this excellent post on Toward Data Science.
If you want to learn more about S3 itself - I highly recommend Andy Warfield’s talk from FAST’23: Building and Operating a Pretty Big Storage System.
Erasure coding is a powerful concept because our backup system can withstand losing an entire storage node and still maintain a full copy of the data. It pairs very nicely with the fact that distributed systems increase reliability exponentially while costs increase linearly. It’s true!. This is how AWS can run S3 with 11 9’s of durability!
Key takeaways
My goal when I chose a NAS was to have a simple and reliable network storage system which could also moonlight as a small homelab, and Synology delivers all that and more. The available packages are solid, and the community-supported offerings are extensive. It’s become a critical part of my workflow both as a live-streaming software developer, and as a BASE jumper with loads of footage to store.
What most surprised me was how useful and intuitive the web-based operating system is. I thought I’d need to configure a remote desktop or VPN, but instead it’s so simple to use any browser to manage the NAS or even drop files onto it. Theo was right, it’s annoyingly good.
I generally sleep well, but I sleep even better knowing all that local storage power is combined with cloud-based archival storage, so that I’ve got many many 9’s of erasure coding backing up my adventure videos.
If you like this type of content please subscribe to my blog or follow me on twitter and send me any questions or comments. You can also ask me questions directly if I’m streaming on Twitch or YouTube.