The case for containers on Lambda (with benchmarks)
Lambda recently improved the cold start performance of container images by up to 15x, but this isn't the only reason you should use them. The tooling, ecosystem, and entire developer culture has moved to container images and you should too.
January 2, 2024
Note: the second part of this post is available here.
When AWS Lambda first introduced support for container-based functions, the initial reactions from the community were mostly negative. Lambda isn’t meant to run large applications, it is meant to run small bits of code, scaled widely by executing many functions simultaneously.
Containers were not only antithetical to the philosophy of Lambda and the serverless mindset writ large, they were also far slower to initialize (or cold start) compared with their zip-based function counterparts.
If we’re being honest, I think the biggest roadblock to adoption was the cold start performance penalty associated with using containers. That penalty has now all but evaporated.
The AWS Lambda team put in tremendous amounts of work and improved the cold-start times by a shocking 15x, according to the paper and talk given by Marc Brooker.
This post focuses on analyzing the performance of container-based Lambda functions with simple, reproducible tests. It also lays out the pros and cons for containers on Lambda. The next post will delve into how the Lambda team pulled off this performance win.
Performance Tests
I set off to test this new container image strategy by creating several identical functions across zip and container-based packaging schemes. These varied from 0mb of additional dependencies, up to the 250mb limit of zip-based Lambda functions. I’m not directly comparing the size of the final image with the size of the zip file, because containers include an OS and system libraries, so they are natively much larger than zip files.
As usual, I’m testing the round trip request time for a cold start from within the same region. I’m not using init duration, which does not include the time to load bytes into the function sandbox.
I created a cold start by updating the function configuration (setting a new environment variable), and then sending a simple test request. The code for this project is open source. I also streamed this entire process live on twitch.
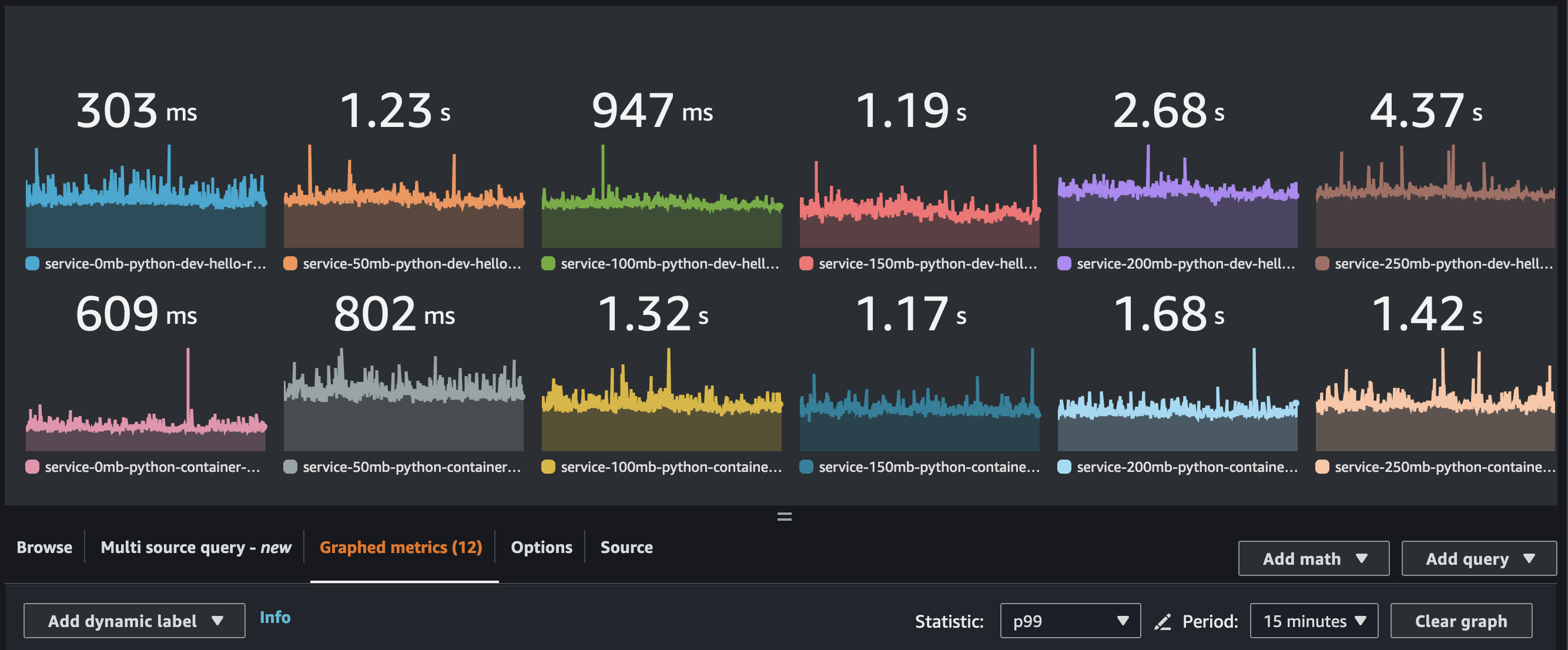
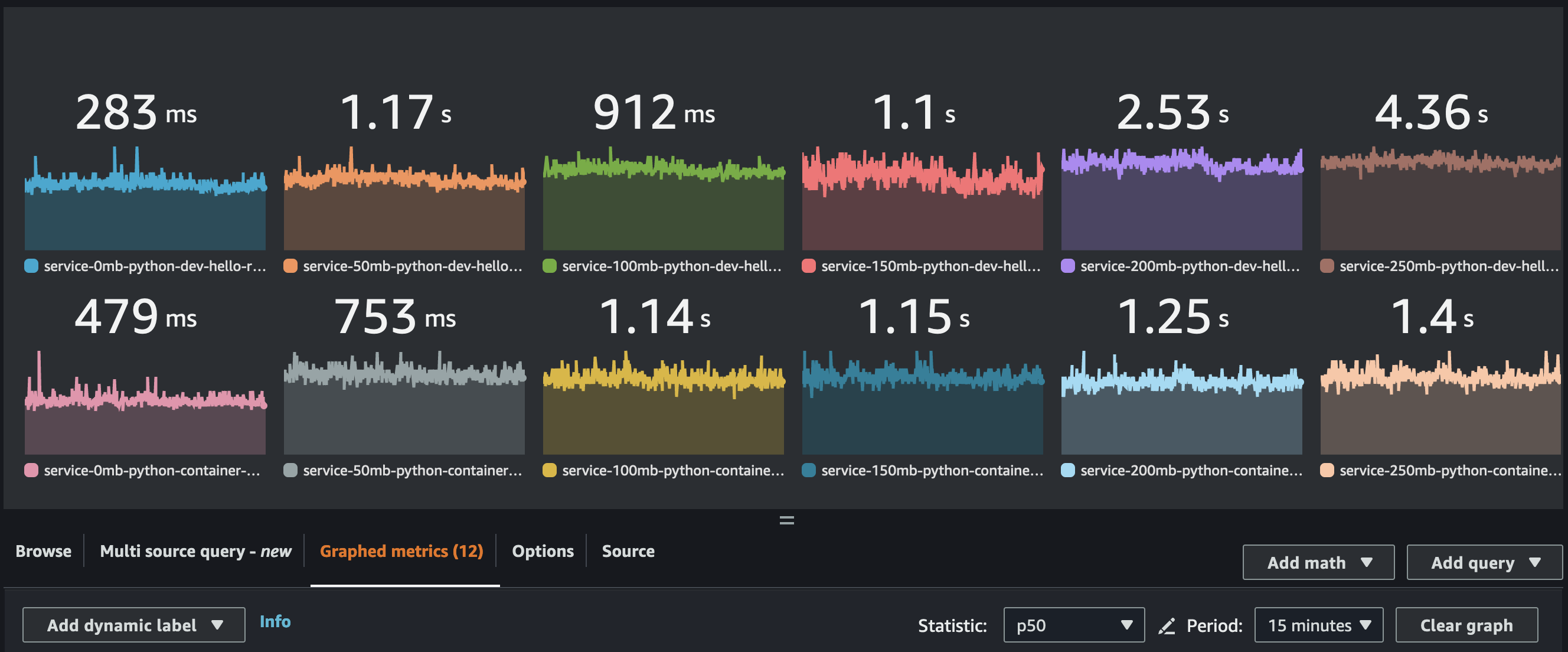
These results were based on the p99 response time, but I’ve included the p50 times for python below.
This first test contains a set of NodeJS functions running Node18.x. After several days and thousands of invocations, we see the final result. The top row represents zip-based Lambda functions, and the bottom row reports container-based Lambda functions (lower is better):
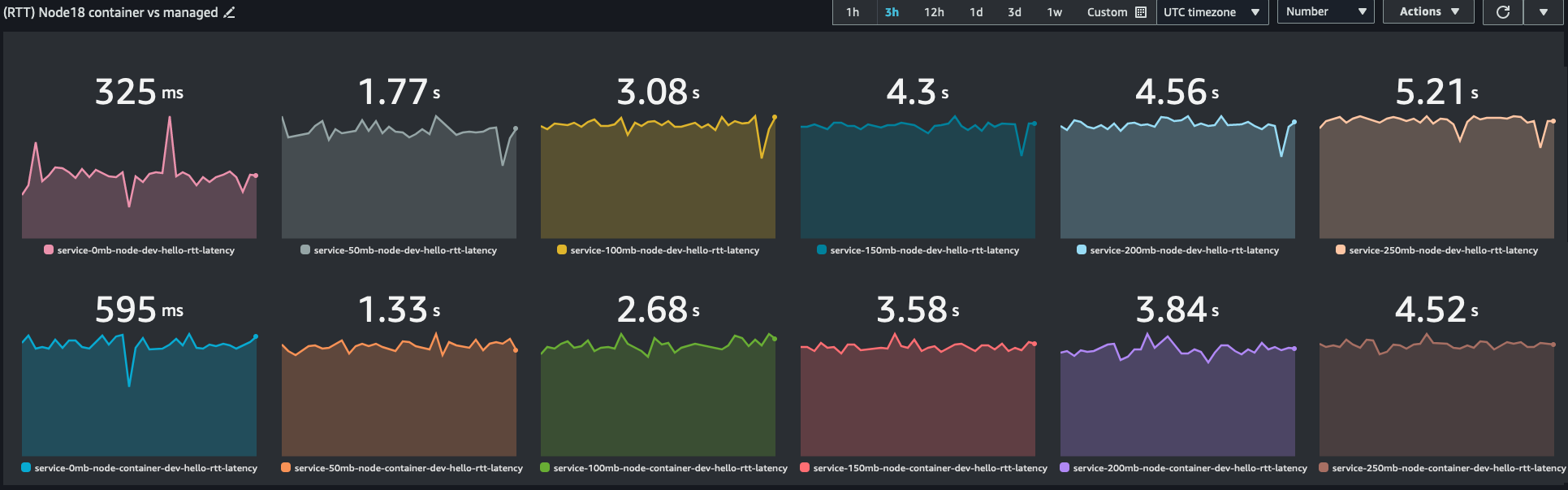 An earlier version of this post reversed the rows. I’ve changed this to be consistent with the python result format. Thanks to those who corrected me!
An earlier version of this post reversed the rows. I’ve changed this to be consistent with the python result format. Thanks to those who corrected me!
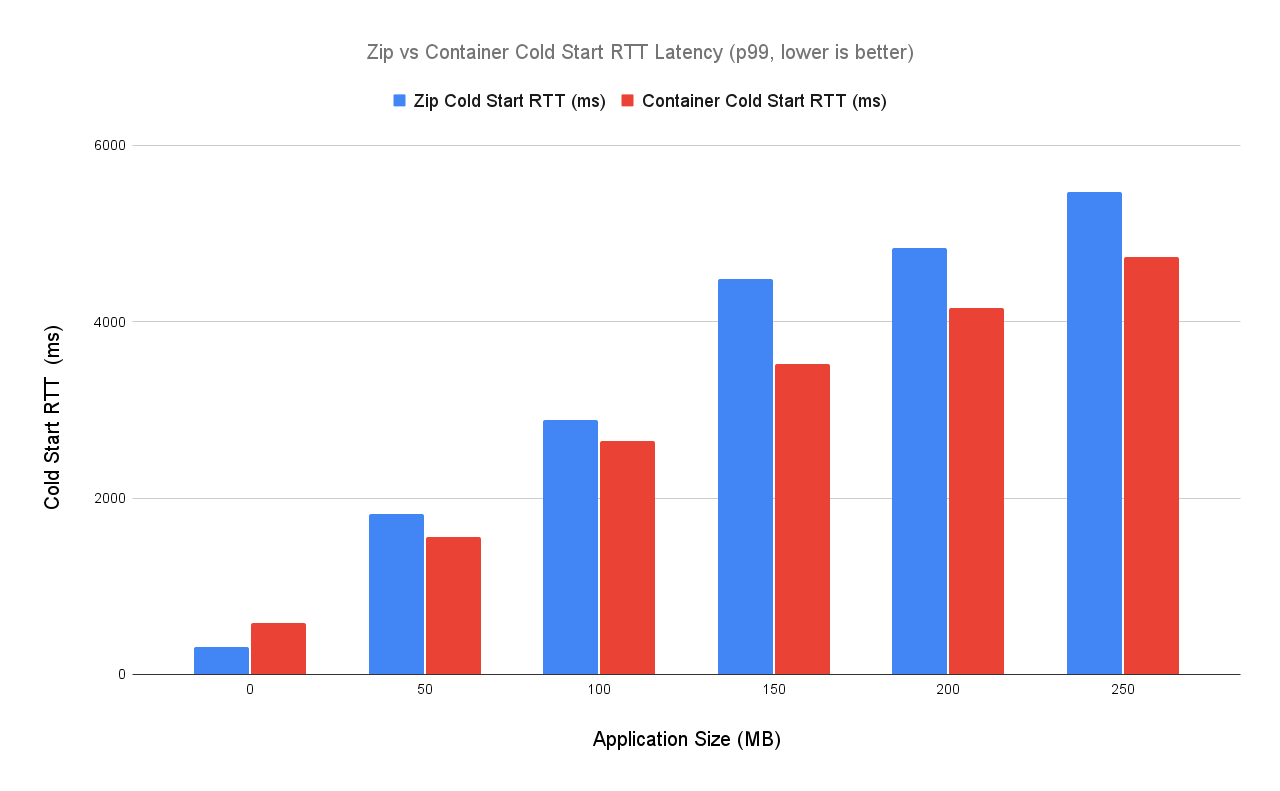
It’s easier to read a bar chart:
The second test was similar and performed with Python functions running Python 3.11. We see a very similar pattern, with slightly more variance and overlap on the lower end of function sizes. Here is the p99:
and here is the p50:
Here it is in chart form, once again looking at p99 over a week:
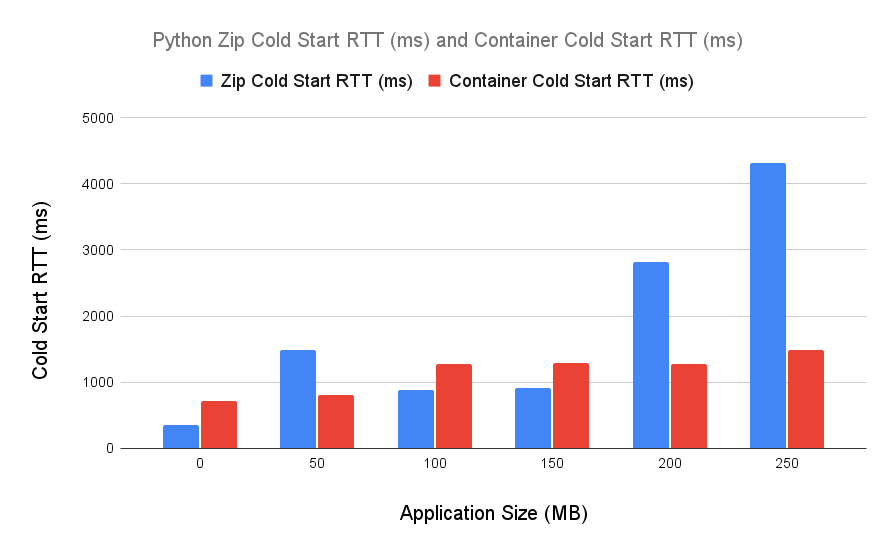
We can see the closer variance at the 100mb and 150mb marks. For the 150mb test I was using Pandas, Flask, and PsycoPG as dependencies. I’m not familiar with the internals of these libraries, so I don’t want to speculate on why these results are slightly unexpected.
My simplest answer is that this is a “real world” test using real dependencies. On top of a managed service like Lambda as well as some amount of network latency in a shared multi-tenant system - many variables could be confounding here.
Performance Takeaways
For NodeJS, beyond ~30mb, container images outperform zip based Lambda functions in cold start performance.
For Python, container images vastly outperform zip based Lambda functions beyond 200mb in size.
This result is incredible, because Lambda container images (in total) are much much larger than the comparative zip files.
I want to stress that the size of dependencies is only one factor that plays into cold starts. Besides size, other factors impact static initialization time including:
- Size and number of heap allocations
- Computations performed during init
- Network requests made during init
These nuances are covered in my talk at AWS re:Invent if you want to dig deeper on the topic of cold starts. All of these individual projects are available on GitHub.
Should you use containers on Lambda?
I am not advocating that you choose containers as a packaging mechanism for your Lambda function based solely on cold start performance.
That said, you should be using containers on Lambda anyway. With these cold start performance improvements, there are very few reasons not to.
While it’s technically true that container images are objectively less efficient means of deploying software applications, container images should be the standard for Lambda functions going forward.
Pros:
- Containers are ubiquitous in software development, and so many tools and developer workflows already revolve around them. It’s easy to find and hire developers who already know how to use containers.
- Multi-stage builds are clear and easy to understand, allowing you easily create the lightest and smallest image possible.
- Graviton on Lambda is quickly becoming the preferred architecture, and container images make x86/ARM cross-compilation easy. This is even more relevant now, as Apple silicon becomes a popular choice for developers.
- Base images for Lambda are updated frequently, and it’s easy enough to auto-deploy the latest image version containing security updates
- Containers allow support larger functions, up to 10gb
- You can use custom runtimes like Bun, Deno, as well as use new runtime versions more easily
- Using the excellent Lambda web adapter extension with a container, you can very easily move a function from Lambda to Fargate or Apprunner if cost becomes an issue. This optionality is of high value, and shouldn’t be overlooked.
- AWS and the broader software development community continues to invest heavily in the container image standard. These improvements to Lambda represent the result of this investment, and I expect that to continue.
Cons:
- To update dependencies managed by Lambda runtimes, you’ll need to re-build your container image and re-deploy your function occasionally. This is something dependabot can easily do, but it could be painful if you have thousands of functions. These updates come free with managed runtimes anyway.
- You do pay for the init duration. Today, Lambda documentation claims that init duration is always billed, but in practice we see that init duration for managed runtimes is not included in the billed duration, logged in the REPORT log line at the end of every execution.
- Slower deployment speeds
- The very first cold start for a new function or function update seems to be quite slow (p99 ~5+ seconds for a large function). This makes the iterate + test loop feel slow. In any production environment, this should be mitigated by invoking an alias (other than
$LATEST). In practice I’ve noticed this goes away if I wait a bit between deployment and invocation. This isn’t great and ideally the Lambda team fixes it soon, but in production it shouldn’t be a problem.
If all of your functions are under 30mb and you’re team is comfortable with zip files, then it may be worth continuing with zip files. For me personally, all new Lambda-backed APIs I create are based on container images using the Lambda web adapter.
Ultimately your team and anyone you hire likely already knows how to use containers. Containers start as fast or faster than zip functions, have more powerful build configurations, and more easily support existing workflows. Finally, containers make it easy to optionally move your application to something like Fargate or AppRunner if costs become a primary concern.
It’s time to use containers on Lambda.
Thanks for reading!
The next post in this series explores how this performance improvement was designed. It’s an example of excellent systems engineering work, and it represents why I’m so bullish on serverless in the long term.
If you like this type of content please subscribe to my blog or reach out on twitter with any questions. You can also ask me questions directly if I’m streaming on Twitch or YouTube.