Stream your data!
Leveraging DynamoDB streams to improve your API performance and service reliability - 8 minutes
November 29, 2021
DynamoDB (DDB) is a compelling datastore choice for Serverless developers for a few key reasons. Dynamo offers a HTTP API, IAM Authorization, serverless pay-per-use billing, and almost unlimited scale when used properly. But there’s more to DynamoDB than a convenient way to store and fetch data for Lambda users.
If you’re new to DynamoDB and Serverless, you may not yet have come across DynamoDB Streams yet. Perhaps you have, but are a bit unclear on how to apply them to your applications. Like the OP of this twitter thread, the compelling use cases for DynamoDB Streams may not be clear to you.
Fear not! In this post we’ll briefly cover what DynamoDB Streams are, and spend most of the post covering specific applications and examples. By the end, you’ll know how and when to use streams to improve API performance, increase resiliency, and build new capabilities.
Configuring a Lambda function to receive DynamoDB stream events can be done through the AWS Console, or via Infrastructure as Code (such as Terraform or CloudFormation). You’ll need to ensure the IAM execution role associated to your Lambda function has policy permissions to read and describe the DynamoDB stream for your table. You must select a StreamSpecification, which is one of four options:
OLD_IMAGE- the Lambda function receives a copy of the item attributes before the change was appliedNEW_IMAGE- the Lambda function receives a copy of the item attributes after the change was appliedNEW_AND_OLD_IMAGES- Your function will get a JSON object with both OLD and NEW items.KEYS_ONLY- Only the key attributes of the item will be sent to your Lambda function.
Now that you’re armed with the knowledge of how to create an integration between a DynamoDB stream and a Lambda function, let’s explore a few use cases to which you may apply this knowledge.
The every day application of streams - Processing asynchronous jobs
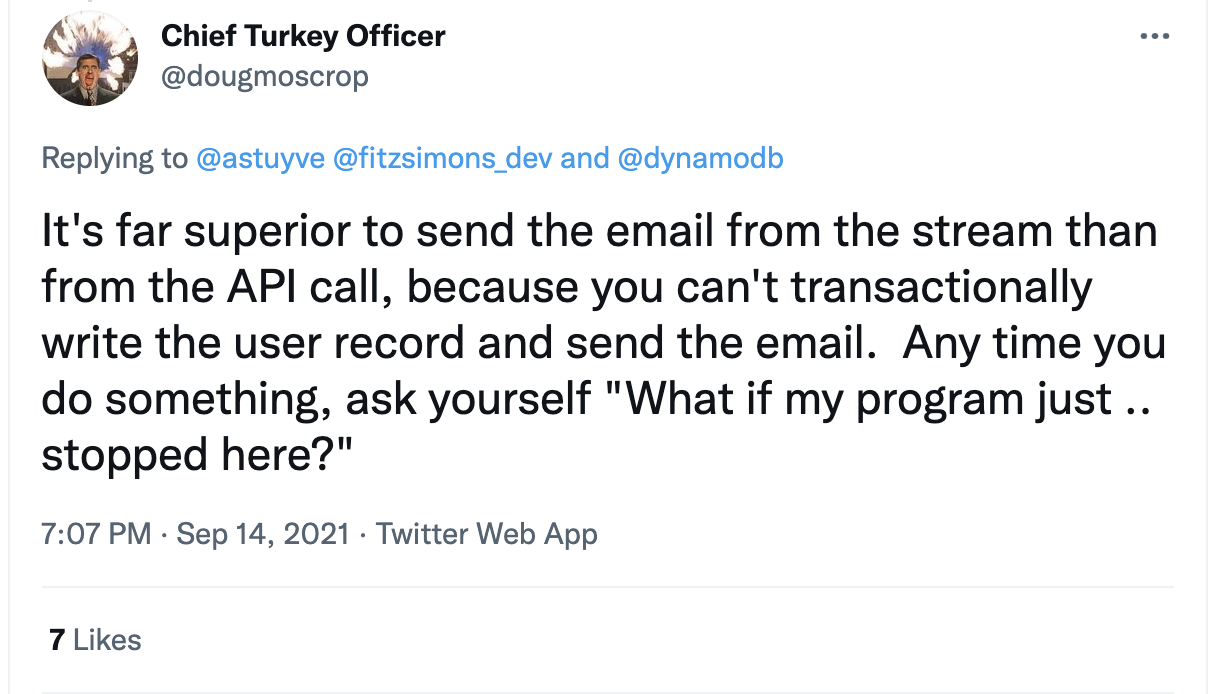
If you’re building a user-facing API, consider shifting all non-essential functionality from the API Function execution into a stream-based, asynchronous Lambda execution. Consider a user registration API endpoint. Beyond simply storing the user data in the user table, you’ll likely want to send the user a confirmation email. You could do that inside of the user registration API endpoint, but what happens if the email service is down briefly, or their API is running slowly?
Instead of forcing the user to endure the downstream effects of your registration business logic, a DynamoDB stream function can send the email asynchronously (and handle retries or failures as needed)!
This also applies to situations where a downstream API is flaky, or runs longer than you’d like. Using a DDB stream, your function can receive a batch of events, allowing you to group updates to the downstream API and retry failures without the user having to wait.
We’ve explored how to speed up and improve reliability of your Serverless applications using DynamoDB streams, next we’ll talk about synchronizing data across services.
Linking services together with Pub/Sub
Serverless applications are often broken into separate services, isolated to their functional domains. However you’ll frequently need to synchronize data between these services. This is often accomplished via a pub/sub mechanism like SQS and SNS, or EventBridge. As we want our APIs to be as performant as possible, we consider broadcasting updates to be outside of the critical path of a system, and thus a great candidate to be made asynchronous with DynamoDB Stream events.
As you can imagine, this asynchronous job pattern can be extended to ETL jobs, analytics, and all kinds of other bookkeeping. But there are more, application-critical aspects which can be accomplished with DynamoDB streams. Let’s look at one specifically - building idempotency into distributed systems.
Advanced DynamoDB Stream Applications - Idempotency
Idempotency is an attribute of a system which means that an operation will be performed exactly once - even if multiple messages are received. You interact with idempotent systems every day, even if you’re not aware of it. Here are a few examples:
- Liking a post on social media
- Placing a bid on an online auction
- RSVP’ing to a calendar event
Since both DynamoDB and Lambda are distributed systems, you’ll need to design your application to receive more than one message at a time. Synchronizing writes to DynamoDB can be done with a conditional update, which is a strongly-consistent write. Let’s consider a system which requires both consistency and asynchrony.
Let’s imagine you’re designing a CI/CD build system. You’ll need to receive a webhook notification from a repository like GitHub, and then execute the CI job. But GitHub notifications might be delivered more than once, and our CI/CD jobs can run for a long time, so we’ll need to build an asynchronous, consistent scheduling system. This is effectively a distributed per-customer priority queue.
You can accomplish this using a combination of DynamoDB conditional updates, and stream events. Here’s the system flow:
- A webhook notification is dispatched from GitHub to our Serverless Application
- We verify the authenticity of the notification, and write the repository data to a DynamoDB table.
- A stream event update triggers our schedule function. We perform necessary bookkeeping (like verifying the user identity, checking for other jobs queued for this repository, etc), and then use a conditional update to change the job status from pending to active. If another function has scheduled the job, this change will fail, so we guarantee only one job will be ran per webhook (even if the notification is received more than once)
- The job status attribute change results in another DDB stream lambda invocation, since we know we’ll only ever see this change once (as it’s being made via a conditional update), we can actually kick off the CI/CD process!
- This pattern can be repeated for status changes (like build passed/failed, etc), as well as sending notifications to the user (or back to GitHub).
This is only one example of a collection of asynchronous data pipeline examples, you can apply this strategy of async, idempotent design to a number of other cases like
- Updating order history after a credit card transaction has processed
- Tracking updates for a shipment
- Hydrating a data store from archived data
and more!
Wrapping it up
DynamoDB Streams are a powerful tool you should consider anytime data processing isn’t absolutely critical for an API to respond. As legendary Serverless developer and enthusiast Doug Moscrop puts it: ‘Ask yourself: “What if my program just … stopped here?”’
Once you’ve started applying DynamoDB streams to your Serverless applications, you’ll discover all kinds of niche applications to clean up business logic and improve performance and functionality!
Good luck out there. Feel free to reach out on twitter with specific questions, or to share something you’re building!