Does AWS Lambda have a silent crash in the runtime?
Understanding what's happening in the "AWS Lambda Silent Crash" blog post, what went wrong, and how to fix it
July 16, 2025
A blog post went very viral in the AWS space recently which asserts that there’s a silent crash in AWS Lambda’s NodeJS runtime when HTTP calls are made from a Lambda function. The post is nearly 23 pages long and mostly pertains to the handling of the issue by AWS (which seems like it could have been better), but ultimately my focus here is on the technical aspects of the post.
This post has been updated to the archive link, as the original has been experiencing a hug of death and is unavailable at the time of publishing.
Background
The author begins by explaining that they investigated this issue to a thorough extent, provided reproducible code, and even confirmed that this code worked fine in ec2 but somehow failed in Lambda. Here’s the summary:
Over a seven-week investigation, I — as CTO and principal engineer for a healthcare-focused AWS
Activate startup — diagnosed and proved a fatal runtime flaw in AWS Lambda that:
• Affected Node.js functions in a VPC
• Caused silent crashes during outbound HTTPS calls
• Produced no logs, no exceptions, and no catchable errors
• Was fully reproducible using minimal test harnesses
Reproducing the issue
Here’s the first snippet of code they provide. The author states this is a nestjs app, but that doesn’t really matter for the purpose of the issue.
@Post('/debug-test-email')
async sendTestEmail() {
this.eventEmitter.emit(events.USER_REGISTERED, {
name: Joe Bloggs,
email: 'email@foo.com', // legitimate email was used for testing
token: 'dummy-token-123',
});
return { message: 'Manual test triggered' };
}
When the handler runs, the author explains, the result is immediately a 201 with the successful expected message, but no email is ever sent:
It emits an event, then immediately returns a response — meaning it always reports success (201),
regardless of whether the downstream email handler succeeds or fails.
But here’s what happened:
• I received the HTTP response
• No email arrived
• No logs appeared in CloudWatch
• No errors fired
• And the USER_REGISTERED event handler was never called
The Lambda simply stopped executing — silently, mid-flight.
The 201 response was intentional — and critical. It allowed the controller to return before downstream
failures occurred, revealing that Lambda wasn’t completing execution even after responding
successfully.
A response was returned, but the function NEVER completed its actual work
Before we move on, I want to add that this is exactly what I’d expect to happen.
The lifecycle of Lambda
So what’s happening here? And why is it expected?
Lambda is famous for “scaling to zero”, where your function code is executed when a request is made, and then “frozen” when the response is completed and there are no other requests to serve. It’s “thawed” again when a new request arrives. Today, a sandbox can only serve one request at a time, and may be reused for subsequent invocations.
After some amount of time, number of invocations, or for any number of possible reasons Lambda will shutdown the sandbox and reap its resources back into the worker pool.
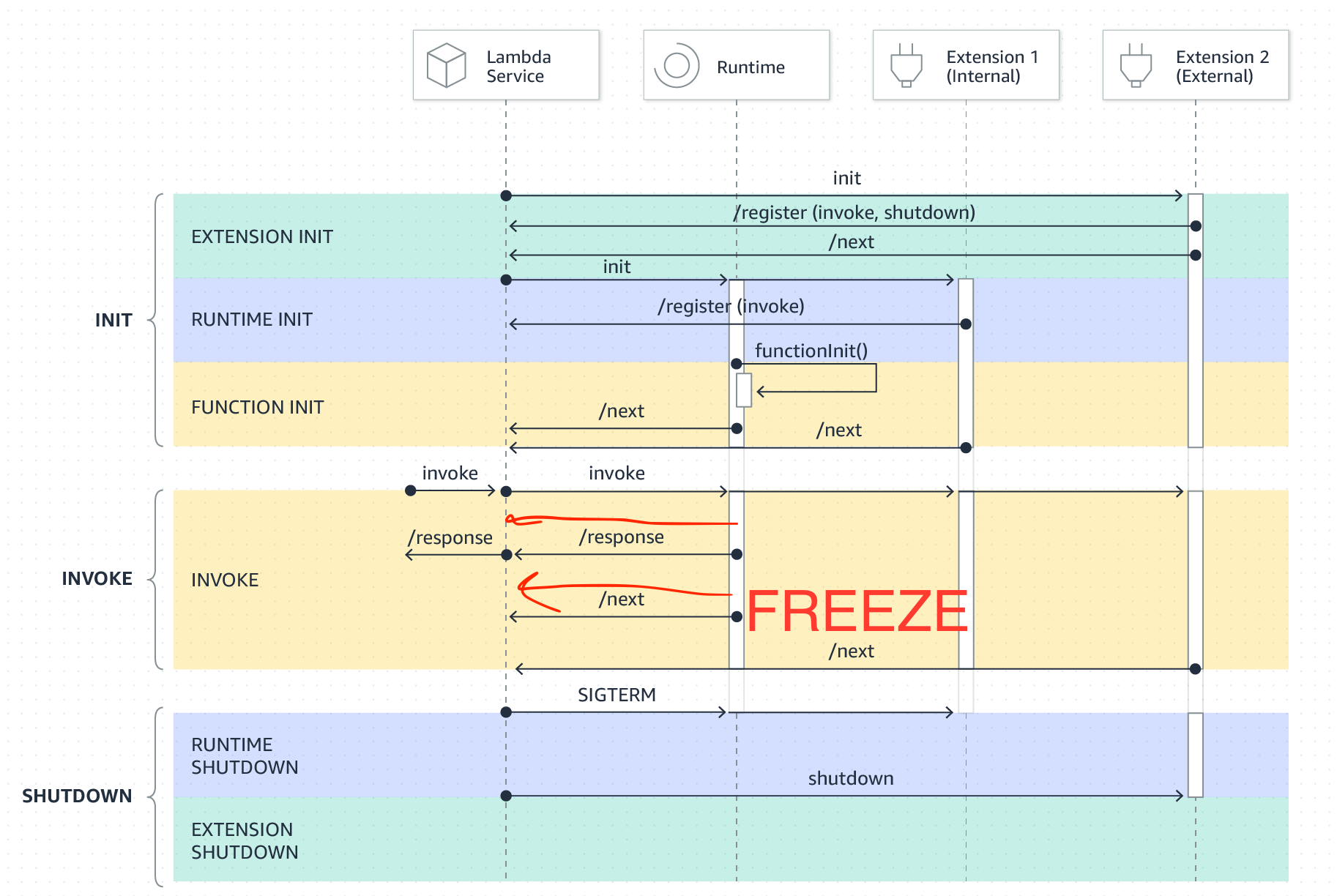
The issue described by the author is rooted in how Lambda handles this lifecycle, specifically the invoke phase. There are two parts to disambiguate here, the Lambda managed runtime (which is nodejs in this case), and Lambda’s Runtime API. We’ll start by examining the Runtime API.
The Runtime API
Lambda exposes an HTTP-based Runtime API, hosted at the link-local address found in the AWS_LAMBDA_RUNTIME_API environment variable. This is a local server which provides the incoming event or request to the Lambda function in JSON format and receives the response from the function once it’s complete. Two of the endpoints are relevant here:
/runtime/invocation/next
and
/runtime/invocation/<AwsRequestId>/response.
For the ease of discussion we’ll call them /next and /response.
Lambda operates as a state machine. Functions call the /next endpoint to receive the next request. When a function completes its request, it sends the result to the /response endpoint, and then calls /next again to get the next request and so on.
The call to /next has three possible return states:
- You receive an invocation response containing a request payload.
- You receive the shutdown event, indicating the sandbox will shut down (only applies to extensions, not your handler, but it is part of the Runtime API) or possibly
- Lambda freezes the CPU because there are no pending requests
When a request arrives, the runtime will thaw the CPU and return a result to
/next.
This is easy to see in the state machine image for Extension development. For now, ignore the extension columns:
Lambda’s Node runtime
The NodeJS runtime isn’t really much of a secret, you can either extract it from the container base images they publish like this, or you can read the runtime interface client code, which interacts with the Runtime API.
When you provide a nodejs function, Lambda looks for it based on the handler method configured for the function. Then it imports your function, and passes it the runtime events from the Runtime API. Then it’s effectively acting as a state machine, ferrying requests to your code, awaiting the result, and sending them back to the runtime.
Putting it all together
So here is how the Node runtime executes your function
- It calls /next to receive the invocation. At this time, the sandbox could receive a new invocation or be frozen!
- After the call to
/nextreturns, it awaits your handler code, - Then it returns the result via the
/responseendpoint through themarkCompletedcallback, which is called via result.then.
Now when we look back at the original code snippet, we see the issue:
@Post('/debug-test-email')
async sendTestEmail() {
this.eventEmitter.emit(events.USER_REGISTERED, {
name: Joe Bloggs,
email: 'email@foo.com, // legitimate email was used for testing
token: 'dummy-token-123',
});
return { message: 'Manual test triggered' };
}
The listener waiting for the USER_REGISTERED event will never run unless subsequent invocations occur frequently enough that Node’s scheduler runs that task! And given that this result is returned basically instantly, that may never happen!
How to actually do this
Now that we’ve jumped through the Lambda Runtime API and Node Runtime and see why this code wouldn’t work, how could you do something like this in Lambda if you wanted to? There are three pretty good options:
- Use Lambda’s NodeJS response streaming to separate the response from the handler’s promise resolution.
- Use a custom runtime
- Use a Lambda extension (internal or external, but internal is easier).
Response Streaming
If your client can receive a chunked response, you can easily return the lightweight response using the streaming API and then perform the async work and resolve your handler’s promise when the work completes.
AWS even published a great blog about it here, but here’s the relevant section:
export const handler = awslambda.streamifyResponse(async (event, responseStream, _context) => {
logger.info("[Function] Received event: ", event);
// Do some stuff with event
let response = await calc_response(event);
// Return response to client
logger.info("[Function] Returning response to client");
responseStream.setContentType('application/json');
responseStream.write(response);
responseStream.end();
await async_task(response);
});
This works great, but there’s an even easier way with
Use a custom runtime.
You can fork the runtime-interface-client and then drive your async tasks to completion after providing the response via /response but before calling the /next endpoint. Bref, the extremely popular PHP runtime for Lambda, already supports this out of the box. Here we can see that Bref will get the response from next, return the result (via sendResponse), and then call the afterInvoke hooks to run any async work you may have queued up:
public function processNextEvent(Handler | RequestHandlerInterface | callable $handler): bool
{
[$event, $context] = $this->waitNextInvocation();
// Expose the context in an environment variable
$this->setEnv('LAMBDA_INVOCATION_CONTEXT', json_encode($context, JSON_THROW_ON_ERROR));
try {
ColdStartTracker::invocationStarted();
Bref::triggerHooks('beforeInvoke');
Bref::events()->beforeInvoke($handler, $event, $context);
$this->ping();
$result = $this->invoker->invoke($handler, $event, $context);
$this->sendResponse($context->getAwsRequestId(), $result);
} catch (Throwable $e) {
$this->signalFailure($context->getAwsRequestId(), $e);
try {
Bref::events()->afterInvoke($handler, $event, $context, null, $e);
} catch (Throwable $e) {
$this->logError($e, $context->getAwsRequestId());
}
return false;
}
// Any error in the afterInvoke hook happens after the response has been sent,
// we can no longer mark the invocation as failed. Instead we log the error.
try {
Bref::events()->afterInvoke($handler, $event, $context, $result);
} catch (Throwable $e) {
$this->logError($e, $context->getAwsRequestId());
return false;
}
return true;
}
Vercel also added support to Lambda via waitUntil to achieve a similar end.
This technique looks quite simple, but of course the downside is that you’re responsible to maintain the nodejs distribution you’re packaging, but I find that’s a pretty low overhead and something that dependabot can help keep updated.
I’d like to see AWS offer this natively.
Use an extension
Lambda Extensions offer a relatively low lift way to add async processing to your Lambda function. You can use an internal or external extension, and AWS recommends an internal extension in their post, but the rest is pretty straightforward.
Configure the handler, and provide an in-memory queue to pass jobs between the handler and the job runner:
import json
import time
import async_processor as ap
from aws_lambda_powertools import Logger
logger = Logger()
def calc_response(event):
logger.info(f"[Function] Calculating response")
time.sleep(1) # Simulate sync work
return {
"message": "hello from extension"
}
# This function is performed after the handler code calls submit_async_task
# and it can continue running after the function returns
def async_task(response):
logger.info(f"[Async task] Starting async task: {json.dumps(response)}")
time.sleep(3) # Simulate async work
logger.info(f"[Async task] Done")
def handler(event, context):
logger.info(f"[Function] Received event: {json.dumps(event)}")
# Calculate response
response = calc_response(event)
# Done calculating response
# call async processor to continue
logger.info(f"[Function] Invoking async task in extension")
ap.start_async_task(async_task, response)
# Return response to client
logger.info(f"[Function] Returning response to client")
return {
"statusCode": 200,
"body": json.dumps(response)
}
Then configure the job runner:
import os
import requests
import threading
import queue
from aws_lambda_powertools import Logger
logger = Logger()
LAMBDA_EXTENSION_NAME = "AsyncProcessor"
# An internal queue used by the handler to notify the extension that it can
# start processing the async task.
async_tasks_queue = queue.Queue()
def start_async_processor():
# Register internal extension
logger.debug(f"[{LAMBDA_EXTENSION_NAME}] Registering with Lambda service...")
response = requests.post(
url=f"http://{os.environ['AWS_LAMBDA_RUNTIME_API']}/2020-01-01/extension/register",
json={'events': ['INVOKE']},
headers={'Lambda-Extension-Name': LAMBDA_EXTENSION_NAME}
)
ext_id = response.headers['Lambda-Extension-Identifier']
logger.debug(f"[{LAMBDA_EXTENSION_NAME}] Registered with ID: {ext_id}")
def process_tasks():
while True:
# Call /next to get notified when there is a new invocation and let
# Lambda know that we are done processing the previous task.
logger.debug(f"[{LAMBDA_EXTENSION_NAME}] Waiting for invocation...")
response = requests.get(
url=f"http://{os.environ['AWS_LAMBDA_RUNTIME_API']}/2020-01-01/extension/event/next",
headers={'Lambda-Extension-Identifier': ext_id},
timeout=None
)
# Get next task from internal queue
logger.debug(f"[{LAMBDA_EXTENSION_NAME}] Woke up, waiting for async task from handler")
async_task, args = async_tasks_queue.get()
if async_task is None:
# No task to run this invocation
logger.debug(f"[{LAMBDA_EXTENSION_NAME}] Received null task. Ignoring.")
else:
# Invoke task
logger.debug(f"[{LAMBDA_EXTENSION_NAME}] Received async task from handler. Starting task.")
async_task(args)
logger.debug(f"[{LAMBDA_EXTENSION_NAME}] Finished processing task")
# Start processing extension events in a separate thread
threading.Thread(target=process_tasks, daemon=True, name='AsyncProcessor').start()
# Used by the function to indicate that there is work that needs to be
# performed by the async task processor
def start_async_task(async_task=None, args=None):
async_tasks_queue.put((async_task, args))
# Starts the async task processor
start_async_processor()
The downside to this solution which is not handled in this example code is handling the shutdown event response from /next. In this case you’ll want to work the queue to exhaustion and then exit the process, but presumably this is left as an exercise to you, dear reader.
If you run this type of logic across multiple language runtimes, it may be worthwhile to write an External Lambda Extension which is runtime agnostic. You might consider rust, which has pretty incredible performance characteristics in Lambda, as I learned when rewriting Datadog’s Next-Generation Lambda Extension.
Should AWS add support for this?
Running async code in Lambda is such a common request that I’d like to see AWS support it in Lambda, as the value prop of the entire product is anchored in them managing the runtime for you.
That said, I don’t think I’d recommend this solution generally. Instead for the author’s stated use case I’d prefer to use a direct API Gateway -> SQS integration here, which can enqueue a message and then allow me to write a Lambda function which can process these messages in batches, handle retries, downstream provider backpressure, and generally build a more robust system.
Presumably that’s why AWS hasn’t done this yet.
What the author got wrong
Beyond a simple misunderstanding of how Lambda works, the author also expected Lambda to work exactly like EC2. But it’s not, and it shouldn’t be. The opinionated nature of Lambda exists specifically to NOT be ec2. Shipping a whole web framework to Lambda does work and can be useful, but the expectations of the runtime are simply not the same as you’d expect in ec2.
For the author to have that, they’ll need to write your own runtime, or look somewhere else.
If you like this type of content please subscribe to my YouTube channel and follow me on twitter to send me any questions or comments. You can also ask me questions directly if I’m streaming on Twitch.