The what, why, and when of Mono-Lambda vs Single Function APIs
An analytical comparison of two common API patterns in Lambda - 8 minutes
July 28, 2021
Almost once per week, I see a question on Twitter, StackOverflow, or Reddit about how to structure Serverless APIs. Like most things in software, the tl;dr is “it depends”. If you’re bored already, just skim the TL;DR and tweet at me with your objections. If not, get ready to dive in!
TL;DR
Single Function APIs:
- More control/granularity over settings, and IAM execution role
- Easy to find logs/log groups
- Smaller package size
- Highest optionality to use API Keys, highly customized authorizers, rate limiting, etc.
- Easier development, as functions are isolated
- Need to pay attention to CF stack limit
- Long deploy times
- More complexity in configuration (vs code)
- Much harder to share code between REST functions
Mono Lambda APIs:
- Super flexible with routing
- Bring your own framework like Express
- Less concern about CF stack limits
- Very easy to share code between routes/resources
- Less overall optionality (need to set authorizer for all functions and handle RBAC in code)
- Combined development experience, need good CI processes
- Larger package size
- More complexity debugging, as all actions route to one log stream
- Less granular IAM permissions
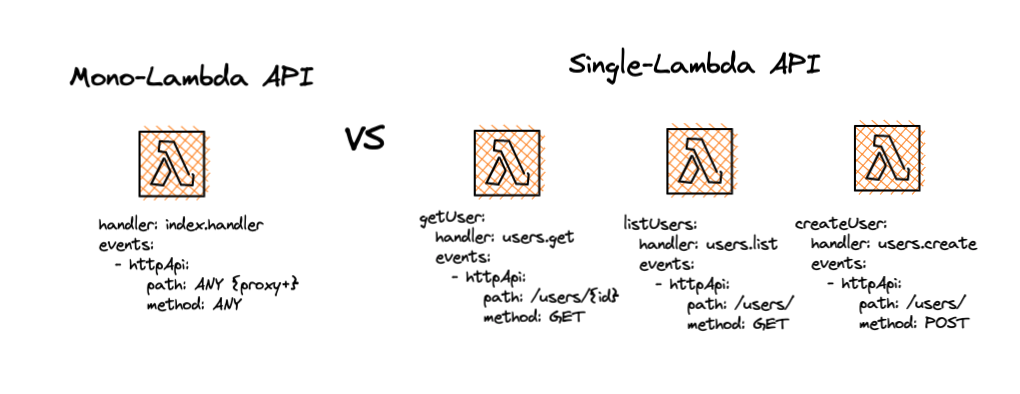
Detailed comparison
But our goal is to take a deep look at these options, their technical consequences, and the factors which may help you make a decision, so “it depends” won’t suffice.
Lambda is frankly, a pretty boring part of Serverless. Boring in a good way - like a healthy DevOps culture where deploys are frequent, painless, and well, boring! If you’re coming from a traditional background of reverse-proxies and servers, you’ve used some kind of domain-based (or top-level route-based) routing of requests, and then usually something like Rails or Express which matches individual routes to business logic.
Serverless APIs sit behind some kind of load balancer as well. Analyzing API Gateway/REST API, HTTP API, and Application Load Balancer (ALB) is a topic for another post, so I’ll skip it. After choosing an API provider, you’ve got two choices when integrating Lambda. You can create individual paths and route those requests to individual Lambda functions (Single-Function), or you can route all requests to one function and then inside your function use a routing system like express to route paths to business logic (Mono-Lambda).
Single-function API
The Single-Function API pattern fits Lambda very naturally. It’s very easy to add a new function to the serverless.yml file, declare a new handler, and you’re done! In the world of Single-Function APIs, there are two additional options:
- You can have a separate function for each action on a resource - GET, LIST, PUT, POST, and DELETE. This keeps code compartmentalized and small.
- You could group all resources under a single function, and then have a case statement depending on the HTTP method and URL parameters passed. This is a bit more complicated but might make sense for you if you’ve got a large number of resources and don’t want to run up against stack resource limits or long-running deploys.
Single-functions offer a few key advantages. A single function has the highest available level of granularity for settings such as:
- Maximum and/or provisioned concurrency
- Function timeouts
- Request bodies
- Query string formatting
- IAM execution role
Perhaps the most important item on the list is the IAM policy that your lambda function executes under. In a Single-Function API, each function can be restricted to exclusively its action. For example, if I had an individual function for an update user API, I can restrict the IAM role to only update calls to DynamoDB, which would guarantee my update function could never delete a record.
Single-functions are often much easier to debug, as each log stream only contains data for individual actions on a resource! When compared to a Mono-Lambda, where all API resources and actions are combined in a log stream, it’s much easier to troubleshoot Single-Function APIs.
You can also greatly reduce your overall package size and footprint with:
package:
individually: true
This can help improve cold start times, but any gain here is likely offset by the distribution of web requests across several functions. DO NOT choose either API pattern based on the perceived risk of cold starts, as they are rare, (getting rarer), short (getting shorter), and easily mitigated via other measures.
Finally, a Single-Function API fits the general design narrative that AWS has for Lambda-based APIs. This means you’ll generally encounter less friction, and have the most flexibility when using API-based rate limiting, API keys, authorizers, and more.
Single-function API design has several downsides too. Cloudformation deploys slow down as more resources are added, and each Lambda function requires several resources beyond just the function (like the execution role and log group).
There is also a 500-resource limit for each Cloudformation stack. If you have a separate function (and role, and group) for each route, for each resource, you can very quickly run into this limit.
Finally, sharing code across many lambda functions can be a difficult endeavor. Lambda layers are great, but they’re explicitly versioned and require a second parallel CI/CD process to deploy. This means if you want to update some shared code (say request/response payload formatter or common utility functions), you’ve got to publish a new version of the layer, and then update its usage in EVERY function (which again, can take a long time).
Example
functions:
getUser:
handler: users.get
events:
- httpApi:
path: /users/{id}
method: GET
listUsers:
handler: users.list
events:
- httpApi:
path: /users/
method: GET
createUser:
handler: users.create
events:
- httpApi:
path: /users/
method: POST
updateUser:
handler: users.update
events:
- httpApi:
path: /users/{id}
method: PUT
deleteUser:
handler: users.delete
events:
- httpApi:
path: /users/{id}
method: DELETE
Mono-Lambda API
The Mono-Lambda design has a few key advantages. It’s more natural for folks coming from traditional backgrounds with Rails or Express. In fact, you can drop your express API into Lambda pretty easily (although I don’t recommend it, as Express adds a fair bit of overhead).
Mono-Lambda APIs are also much simpler to consider from a release and deployment standpoint. This might be the biggest selling point of a Mono-Lambda API because, to me, the most important aspect of a software team is its ability to deploy software as frequently as possible.
I oftentimes find folks with extremely complicated release processes for Single-Function APIs, caused by hundreds of Lambda functions and multiple shared libraries (via layers or private packages). If your organization doesn’t have the resources to devote towards enabling shared code to be deployed and released to Single-Function APIs quickly and safely, a Mono-Lambda is a good choice.
The uniform configuration of a Mono-Lambda API can be a blessing or a curse. If your problem domain encompasses numerous resources with similar actions and behaviors, and you’re using a single-table DynamoDB pattern, the IAM policy for each resource is probably very similar. This means you can generate a reasonably strict policy which still allows the Mono-Lambda API to perform necessary operations, without being over permissive.
With a Mono-Lambda API, you’ll be doing things like routing, request format validation, access control, and throttling inside of your Lambda function. This is fine for many people, as Express/Koa/etc all have robust libraries you can use, and developers are likely already familiar with how to do this. If you’re not using the advanced features of API Gateway, it makes a lot of sense to consider a Mono-Lambda API.
If you don’t care about those advanced API Gateway features or losing granularity on IAM/concurrency/timeout settings, the biggest downside of a Mono-Lambda API is that the AWS console and Cloudwatch can be a bit of a mess to work with. By default, logs for the entire function go to one stream. Since your function processes different resources, it can be hard to trace. I’d suggest writing highly structured log messages using a custom logger, and then relying on Cloudwatch log insights to filter.
That can be slow, and there are a ton of 3rd party options to help manage this (Full disclosure - I work at one). So explore your options and try many of them!
Example
functions:
app:
handler: index.handler
events:
- httpApi:
path: ANY {proxy+}
method: ANY
Closing thoughts
Mono-Lambda vs Single-Function isn’t a hard-and-fast choice, but rather a spectrum, with most users trying a combination of both in the long term.
I think a Mono-Lambda is a great default choice, and since it’s easy to split out Serverless functions down the line, it’s not a one-way choice.
When I find a use case for highly specific permissions, want to use an API gateway feature like API Keys, or require a single responsibility Lambda function, then I’ll use one!
Good luck out there. Feel free to reach out on twitter with specific questions, or to share something you’re building!