Introducing Lambda SnapStart
A first look at the new way to beat cold starts - 6 minutes
November 28, 2022
Introducing Snap Start for Lambda
Today, AWS announced a new feature called SnapStart for Lambda. SnapStart is a feature aimed at reducing the duration of Cold Starts, which can be especially painful for Java environments. SnapStart is now available for Java 11 functions.
SnapStart works by taking a snapshot of your function just before the invocation begins, and then storing that snapshot in a multi-tiered cache in order to make subsequent Lambda container initializations much faster.
This snapshot capability is powered by MicroVM Snapshot technology inside FireCracker, the underlying MicroVM framework used by Lambda as well as AWS Fargate. In practice this means function handler code can start running with sub-second latency (up to 10x faster).
SnapStart is available initially for Java (Amazon Corretto 11), but given that the underlying system providing this capability is runtime-agnostic, it seems likely we’ll see SnapStart support for other runtimes very soon.
How does it work?
Let’s recall this slide from Julian Wood’s 2021 re:Invent talk, Best practices of advanced serverless developers:
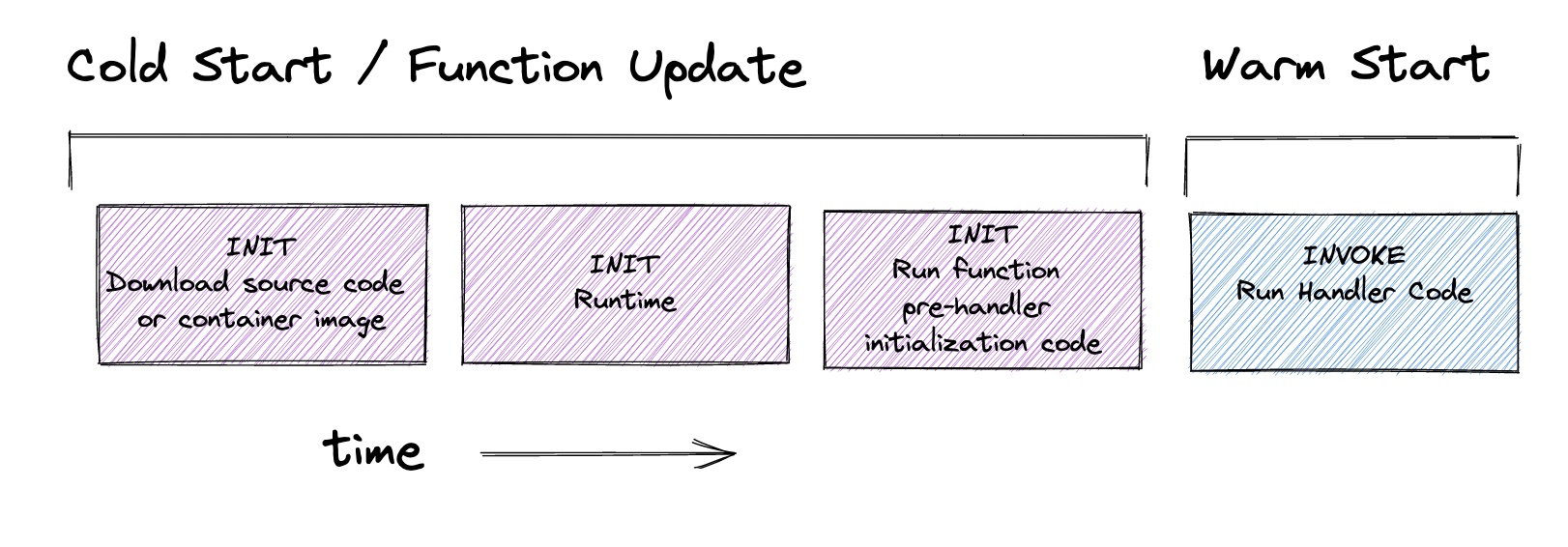
We see that a traditional Lambda invocation (known as an on-demand invocation) begins by the Lambda placement service creating a new execution environment. Your code (or open-container image) is downloaded to the environment, and the runtime is initialized. Then your handler is loaded, and finally your handler is executed.
Now with SnapStart, a snapshot is taken after a new version of the function is created.
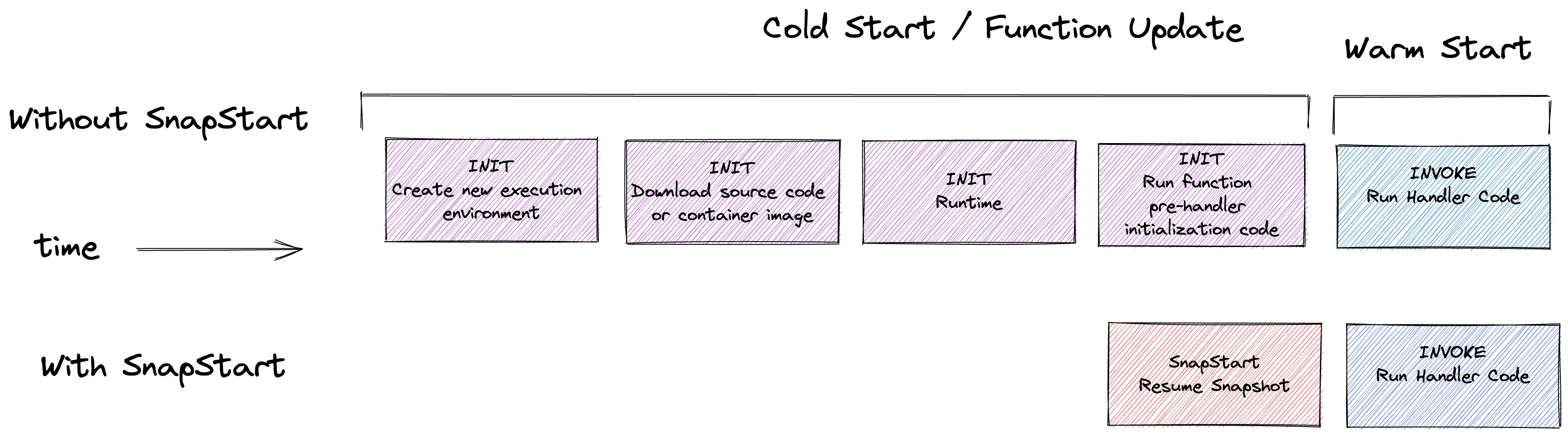
Creating and publishing a new Version takes some additional time, compared to simply using $LATEST. Thankfully snapshots are somewhat long-lived. They are only reaped by Lambda if the function is not invoked for a couple of weeks, then the next invocation would be on-demand and generate a new snapshot.
Once the snapshot is recorded, all new concurrent invocations to fully qualified Lambda ARNs will utilize the snapshot to resume. This is where the payoff occurs, as resuming a snapshot can be up to 10x faster than creating and initializing a new Lambda execution environment.
One important note is that Snap Start doesn’t change anything for serial “warm” invocations. Only a new request or event triggering a concurrent invocation (where there is not a warm Lambda container to receive a new invocation) will use SnapStart.
What’s in a snapshot?
Snapshots contain both memory and disk state of the function after it’s been initialized (but before the invocation has begun). Snapshot data is chunked into 512kb fragments, and cached in a multi-tier strategy.
When a Function snapshot resumes, it will only load chunks required by the function code itself. This is pretty clever, and I presume this is done using mmap’s MAP_PRIVATE, as documented in the firecracker repo. However - reads to the snapshot memory or disk are lazy-loaded. This means there may be some latency when referencing variables or other data, as the entire function code may not be loaded when resumed, and don’t occur until after a specific location is accessed.
Some important caveats
SnapStart is only usable when invoking fully qualified Lambda ARNs, which means publishing and invoking an specific function version. AWS always recommends using versions for your Lambda integrations as a matter of best practice, but the simple fact is that our development tools (including AWS-backed CDK and SAM) don’t do this as a default.
This means you’ll likely need to make some changes to your infrastructure-as-code tool if you want to take advantage of SnapStart. As a quick reminder, here’s the difference between an unqualified and qualified function ARN. Qualified ARN:
arn:aws:lambda:aws-region:acct-id:function:helloworld:42
Unqualified ARN:
arn:aws:lambda:aws-region:acct-id:function:helloworld
Pricing
Free!! Free is good. I like free.
Randomness and Uniqueness
MicroVM Snapshots have inherent Uniqueness and Randomness concerns, as a snapshot of memory from a singular invocation will be re-used across multiple (perhaps concurrent) invocations. Fortunately this is mitigated by using cryptographically-secure pseudo-random number generators, instead of PRNGs.
AWS also provides a tool to help check to ensure your function doesn’t assume uniqueness, it’s available here
Ephemeral Data and Temporary Credentials
Another consequence of snapshot-resuming is that ephemeral data or temporary credentials have no expiry guarantees. For example; a library which creates an expiring token at function may find that the token is expired when a new container spins up via SnapStart. Therefore, it’s best practice to verify that any ephemeral tokens or data is valid before using it.
Network connections
The last likely pitfall that serverless developers may fall into is storing and resuming network connections. It’s common practice to memoize a database or network connection outside of the function handler, so it’s available for subsequent invocations. This won’t work with SnapStart, because although the the HTTP or Database library is still initialized, the actual socket connection can’t be transferred or multiplexed to the new containers. So you’ll have to re-establish these connections.
The documentation doesn’t cover VPC connections, but I anticipate SnapStart won’t help here either; as function containers are created and then their network devices are attached to a VPC, versus the somewhat common theory that functions will be created inside a VPC.
My thoughts
To me, SnapStart feels like the way Lambda should have been designed from the very beginning. If the claimed performance improvements hold up, it’ll change the way Lambda scaling is perceived in the Serverless space and the industry at large. That said, while SnapStart seems truly compelling, I can’t help but consider the developer experience.
Although I think SnapStart likely represents the defacto standard for all new Lambda functions going forward, our tools need to adapt before SnapStart is easy to use.
Using SnapStart means only invoking qualified ARNs (via versioning). As I previously discussed, this isn’t the default for our tools and likely means building more complex deployment processes. It also means we, as Serverless developers, need to improve how we build and ship Serverless applications.
Wrapping up
If you want to learn more about SnapStart, you can check out the full documentation
That’s all I’ve got for you today. If you’ve got questions, or I missed something - feel free to reach out to me on twitter and let me know!