Understanding AWS Lambda Proactive Initialization
AWS Lambda warms up your functions, such that 50%-85% of Lambda Sandbox initializations don't increase latency for users. In this article we'll define Proactive Initialization, observe its frequency, and help you identify invocations where your cold starts weren't really that cold.
July 13, 2023
This post is both longer and more popular than I anticipated, so I’ve decided to add a quick summary:
TL;DR
- Lambda occasionally pre-initializes execution environments to reduce the number of cold start invocations.
- This does NOT mean you’ll never have a cold start
- The percentage of true cold start initializations to proactive initializations varies depending on many factors, but you can clearly observe it.
- Depending on your workload and latency tolerences, you may need Provisioned Concurrency.
Lambda Proactive Initialization
In March 2023, AWS updated the documentation for the Lambda Function Lifecycle, and included this interesting new statement:
“For functions using unreserved (on-demand) concurrency, Lambda may proactively initialize a function instance, even if there’s no invocation.”
It goes on to say:
“When this happens, you can observe an unexpected time gap between your function’s initialization and invocation phases. This gap can appear similar to what you would observe when using provisioned concurrency.”
This sentence, buried in the docs, indicates something not widely known about AWS Lambda; that AWS may warm your functions to reduce the impact and frequency of cold starts, even when used on-demand!
Today, July 13th - they clarified this further: “For functions using unreserved (on-demand) concurrency, Lambda occasionally pre-initializes execution environments to reduce the number of cold start invocations. For example, Lambda might initialize a new execution environment to replace an execution environment that is about to be shut down. If a pre-initialized execution environment becomes available while Lambda is initializing a new execution environment to process an invocation, Lambda can use the pre-initialized execution environment.”
This update is no accident. In fact it’s the result of several months I spent working closely with the AWS Lambda service team:

1 - Execution environments (see ‘Init Phase’ section), and 2 - Invocation Initialization gap
In this post we’ll define what a Proactively Initialized Lambda Sandbox is, how they differ from cold starts, and measure how frequently they occur.
Distributed Tracing & AWS Lambda Proactive Initialization
This adventure began when I noticed what appeared to be a bug in a distributed trace. The trace correctly measured the Lambda initialization phase, but appeared to show the first invocation occurring several minutes after initialization. This can happen with SnapStart, or Provisioned Concurrency - but this function wasn’t using either of these capabilities and was otherwise entirely unremarkable.
Here’s what the flamegraph looks like:
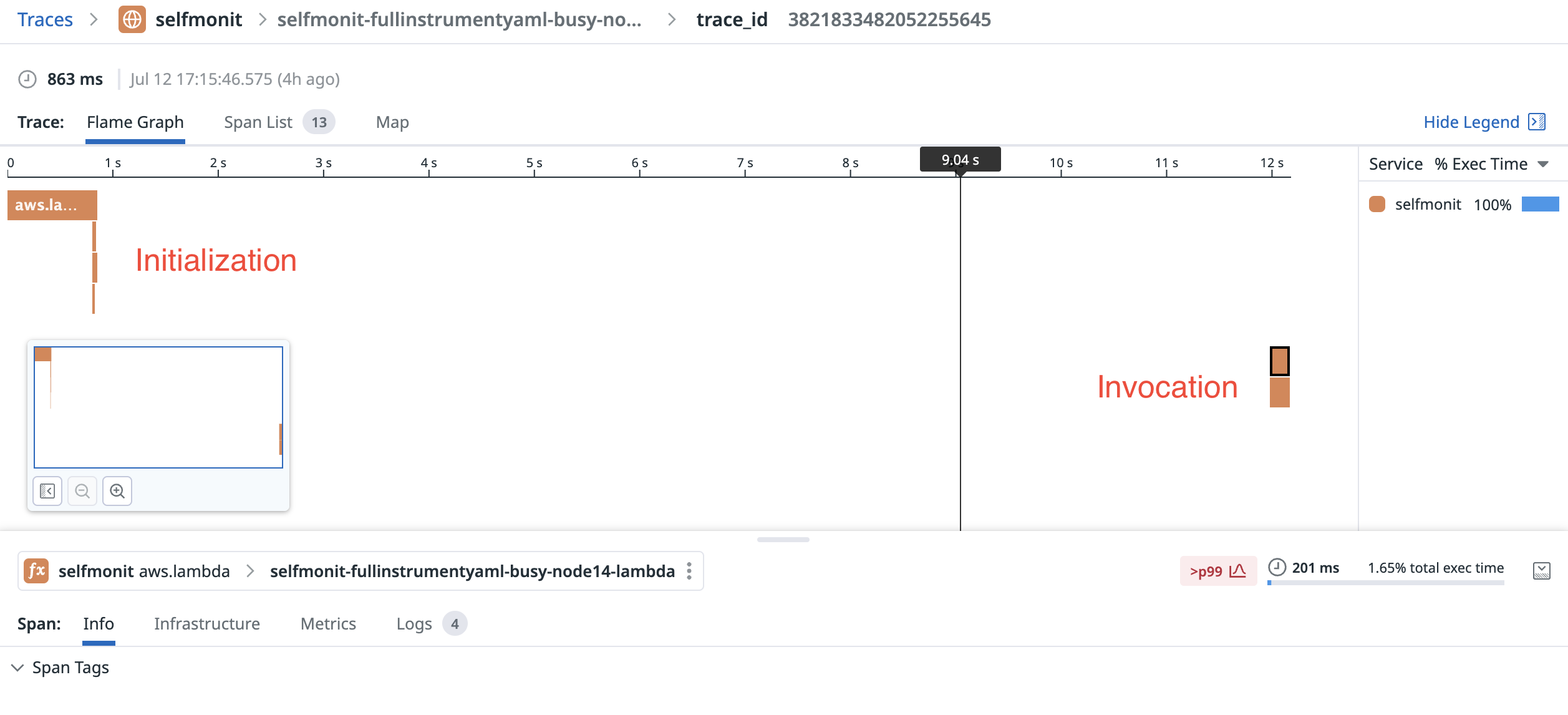
We can see a massive gap between function initialization and invocation - in this case the invocation request wasn’t even made by the client until ~12 seconds after the sandbox was warmed up.
We’ve also observed cases where Initialization occurs several minutes before the first invocation, in this case the gap was nearly 6 minutes:
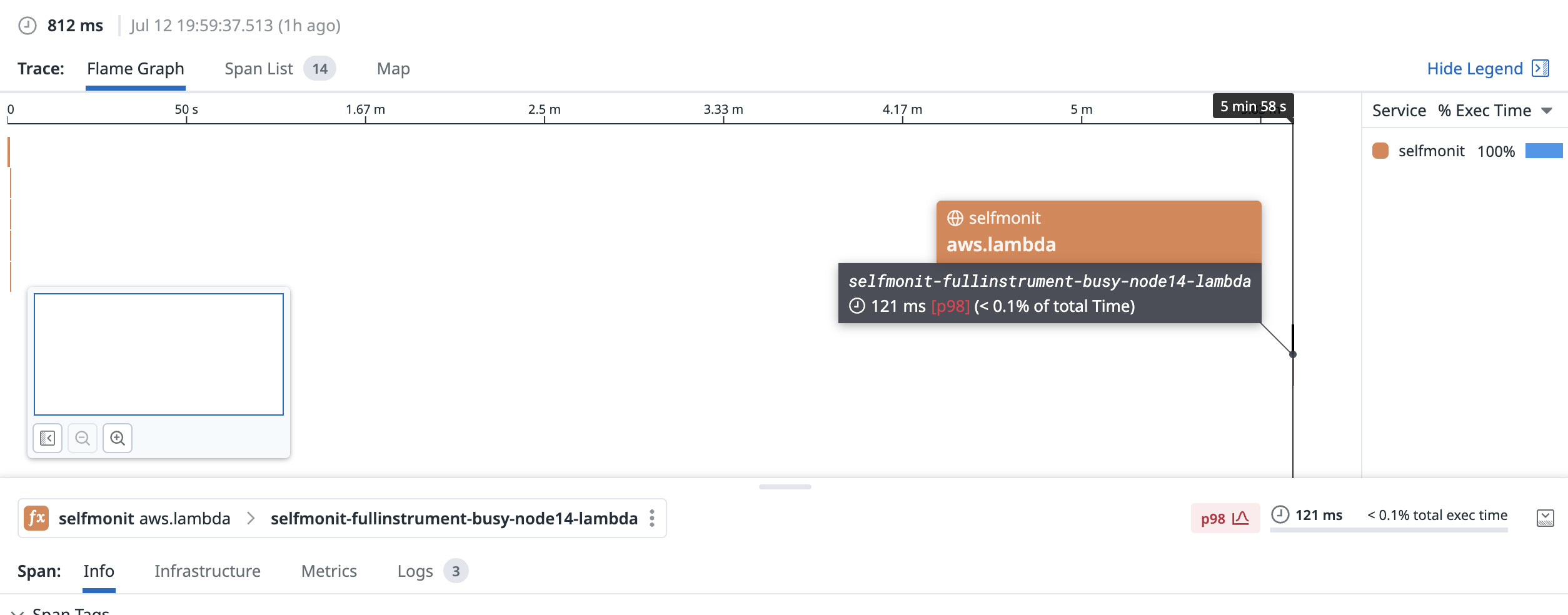
After much discussion with the AWS Lambda Support team - I learned that I was observing a Proactively Initialized Lambda Sandbox.
It’s difficult to discuss Proactive Initialization at a technical level without first defining a cold start, so let’s start there.
Defining a Cold Start
AWS Lambda defines a cold start in the documentation as the time taken to download your application code and start the application runtime.
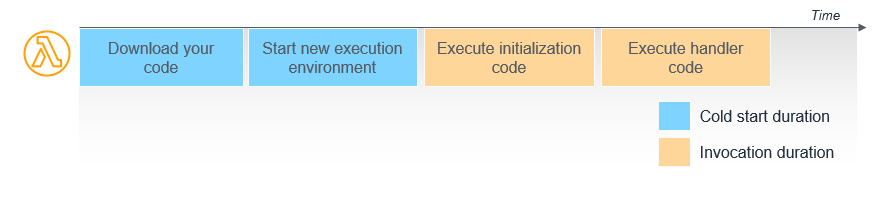
Until now, it was understood that cold starts would happen for any function invocation where there is no idle, initialized sandbox ready to receive the request (absent using SnapStart or Provisioned Concurrency).
When a function invocation experiences a cold start, users experience something ranging from 100ms to several additional seconds of latency, and developers observe an Init Duration reported in the CloudWatch logs for the invocation.
With cold starts defined, let’s expand this to understand the definition of Proactive Initialization.
Technical Definition of Proactive Initialization
Proactive Initialization occurs when a Lambda Function Sandbox is initialized without a pending Lambda invocation.
As a developer this is desirable, because each proactively initialized sandbox means one less painful cold start which otherwise a user would experience.
As a user of the application powered by Lambda, it’s as if there were never any cold starts at all.
When a function is proactively initialized, the user making the first request to the sandbox does not experience a cold start (similar to Provisioned Concurrency, but for free).
Aligned interests in the Shared Responsibility Model
Proactive Initialization serves the interests of both the team running AWS Lambda and developers running applications on Lambda.
We know that from an economic perspective, AWS Lambda wants to run as many functions on the same server as possible (yes, serverless has servers…). We also know that developers want their cold starts to be as infrequent and fast as possible.
Understanding the fact that cold starts absorb valuable CPU time in a shared, multi-tenant system, (time which is currently not billed) it’s clear that any option AWS has to minimize this time is mutually beneficial.
AWS Lambda is a distributed service. Worker fleets need to be redeployed, scaled out, scaled in, and respond to failures in the underlying hardware. After all - everything fails all the time.
{kind=link}
This means that even with steady-state throughput, Lambda will need to rotate function sandboxes for users over the course of hours or days. AWS does not publish minimum or maximum lease durations for a function sandbox, although in practice I’ve observed ~7 minutes on the low side and several hours on the high side.
Update: An AWS whitepaper states that the maximum lease lifetime for a worker sandbox is 14 hours. Thanks to Philip Potter for pointing this out!
The service also needs to run efficiently, combining as many functions onto one machine as possible. In distributed systems parlance, this is known as bin packing (aka shoving as much stuff as possible into the same bucket).
The less time spent initializing functions which AWS knows will serve invocations, the better for everyone.
When Lambda will Proactively Initialize your function
There are some logical conditions which can lead to Proactive Initialization - deployments and eager assignments.
Consider we’re working with a function which at steady state experiences 100 concurrent invocations. When you deploy a change to your function (or function configuration), AWS can make a pretty reasonable guess that you’ll continue to invoke that same function 100 times concurrently after the deployment finishes.
Instead of waiting for each invocation to trigger a cold start, AWS will automatically re-provision (roughly) 100 sandboxes to absorb that load when the deployment finishes. Some users will still experience the full cold start duration, but some won’t (depending on the request duration and when requests arrive).
This can similarly occur when Lambda needs to rotate or roll out new Lambda Worker hosts.
These aren’t novel optimizations in the realm of distributed systems, but this is the first time AWS has confirmed they make these optimizations.
Proactive Initialization due to Eager Assignments
In certain cases, Proactive Initialization is a consequence of natural traffic patterns in your application where an internal system called the AWS Lambda Placement Service will assign pending lambda invocation requests to sandboxes as they become available.
Here’s how it works:
Consider a running Lambda function which is currently processing a request. In this case, only one sandbox is running. When a new request triggers a Lambda function, AWS’s Lambda Control Plane will check for available warm sandboxes to run your request.
If none are available, a new sandbox is initialized by the Control Plane:
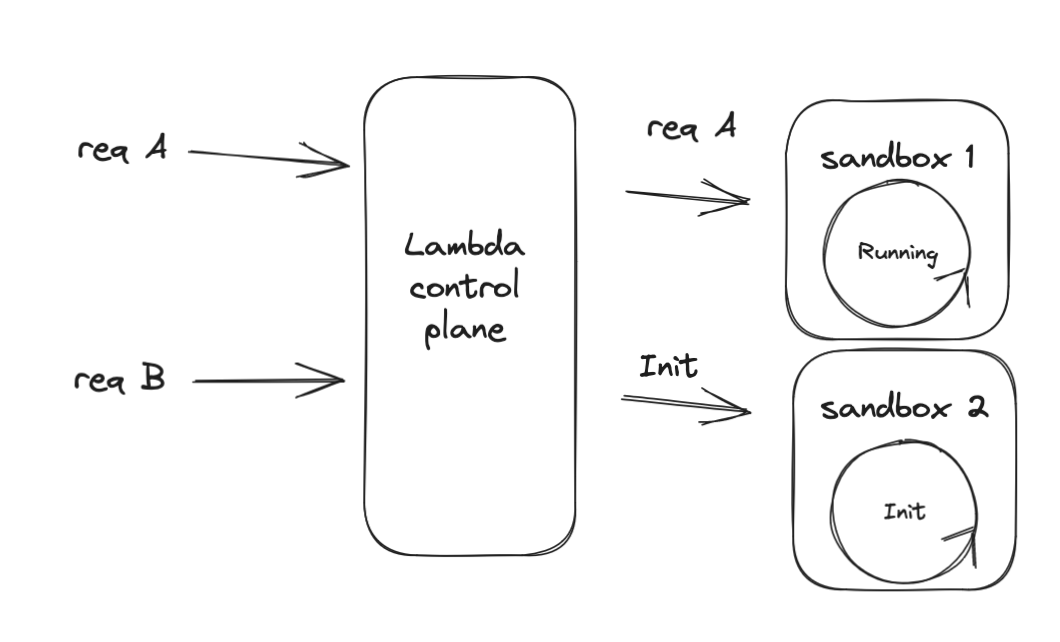
However it’s possible that in this time that a warm sandbox completes a request and is ready to receive a new request. In this case, Lambda will assign the request to the newly-free warm sandbox.
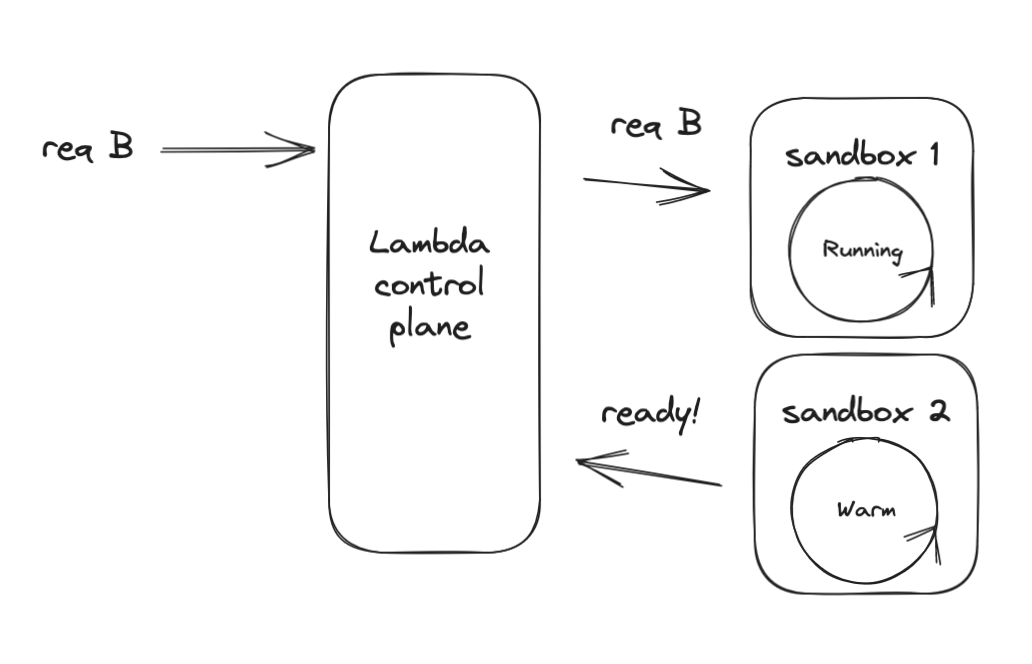
The new sandbox which was created now has no request to serve. It is still kept warm, and can serve new requests - but a user did not wait for the sandbox to warm up.
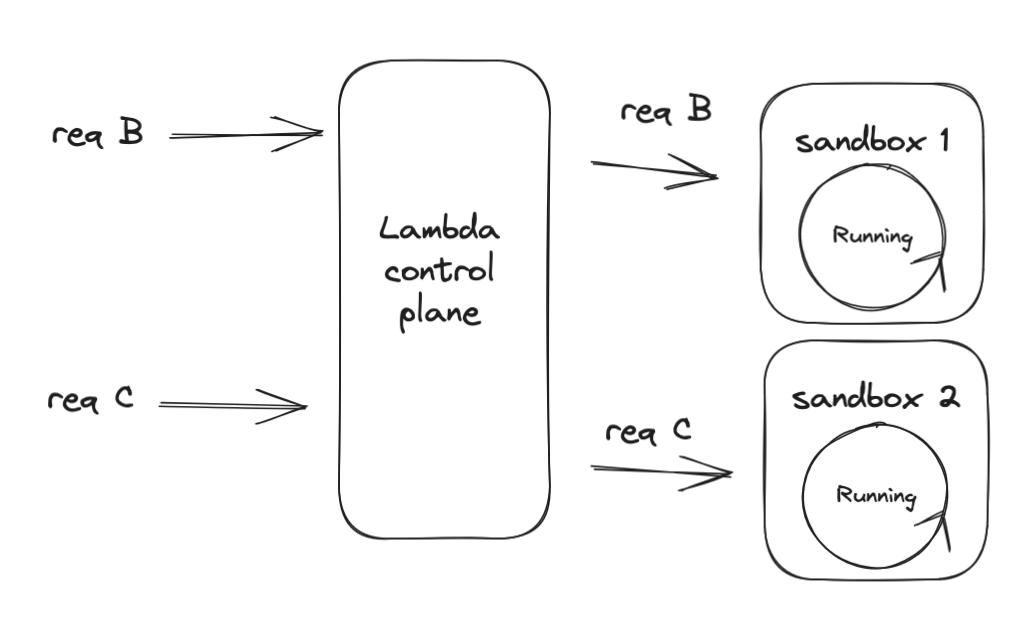
This is a proactive initialization.
When a new request arrives, it can be routed to this warm container with no delay!
Request B did spend some time waiting for a sandbox (but less than the full duration of a cold start). This latency is not reflected in the duration metric, which is why it’s important to monitor the end to end latency of any synchronous request through the calling service! (Like API Gateway)
Detecting Proactive Initializations
We can leverage the fact that AWS Lambda functions must initialize within 10 seconds, otherwise the Lambda runtime is re-initialized from scratch. Using this fact, we can safely infer that a Lambda Sandbox is proactively initialized when:
- Greater than 10 seconds has passed between the earliest part of function initialization first invocation processed and
- We’re processing the first invocation for a sandbox.
Both of these are easily tested, here’s the code for Node:
const coldStartSystemTime = new Date()
let functionDidColdStart = true
export async function handler(event, context) {
if (functionDidColdStart) {
const handlerWrappedTime = new Date()
const proactiveInitialization = handlerWrappedTime - coldStartSystemTime > 10000 ? true : false
console.log({proactiveInitialization})
functionDidColdStart = false
}
return {
statusCode: 200,
body: JSON.stringify({success: true})
}
}
and for Python:
import json
import time
init_time = time.time_ns() // 1_000_000
cold_start = True
def hello(event, context):
global cold_start
if cold_start:
now = time.time_ns() // 1_000_000
cold_start = False
proactive_initialization = False
if (now - init_time) > 10_000:
proactive_initialization = True
print(f'{{proactiveInitialization: {proactive_initialization}}}')
body = {
"message": "Go Serverless v1.0! Your function executed successfully!",
"input": event
}
response = {
"statusCode": 200,
"body": json.dumps(body)
}
return response
Frequency of Proactive Initializations
At low throughput, there are virtually no proactive initializations for AWS Lambda functions. But I called this function over and over in an endless loop (thanks to AWS credits provided by the AWS Community Builder program), and noticed that almost 65% of my cold starts were actually proactive initializations, and did not contribute to user-facing latency.
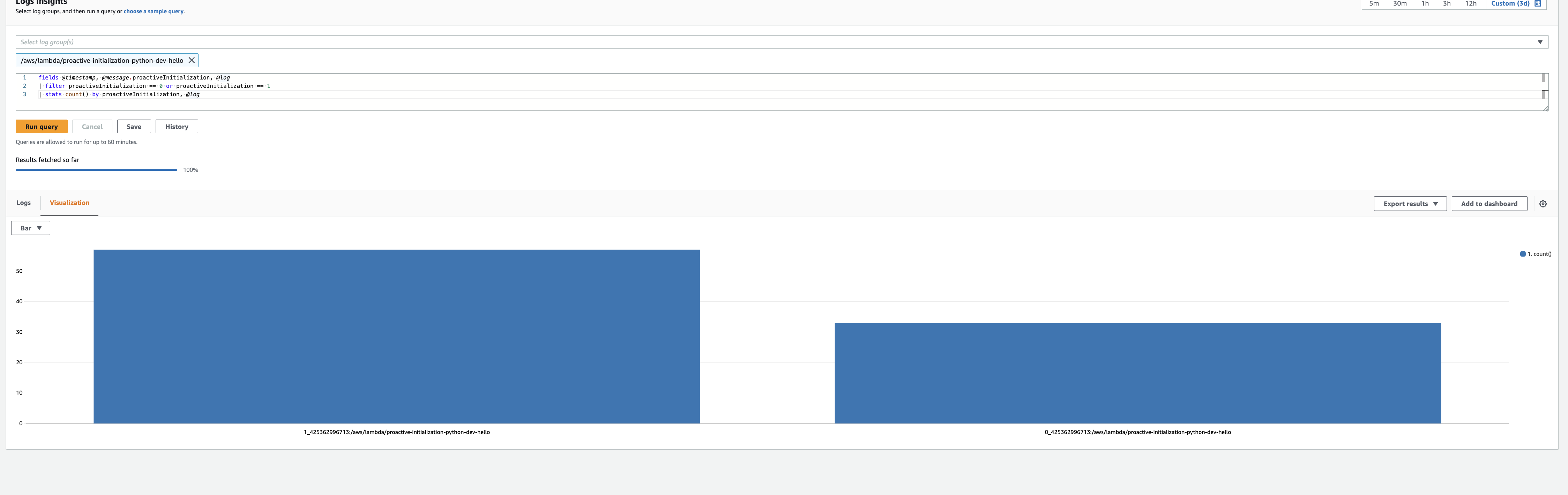
Here’s the query:
fields @timestamp, @message.proactiveInitialization
| filter proactiveInitialization == 0 or proactiveInitialization == 1
| stats count() by proactiveInitialization
Here’s the detailed breakdown, note that each bar reflects the sum of initializations:
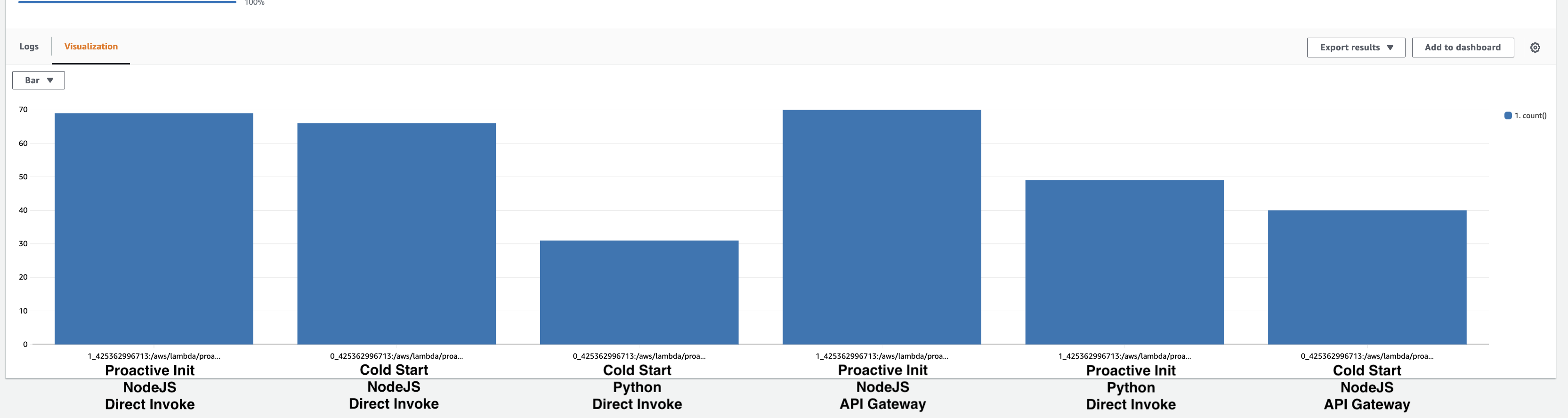
Running this query over several days across multiple runtimes and invocation methods, I observed between 50% and 75% of initializations were Proactive (versus 50% to 25% which were true Cold Starts):
We can see this reflected in the cumulative sum of invocations for a one day window. Here’s a python function invoked at a very high frequency:
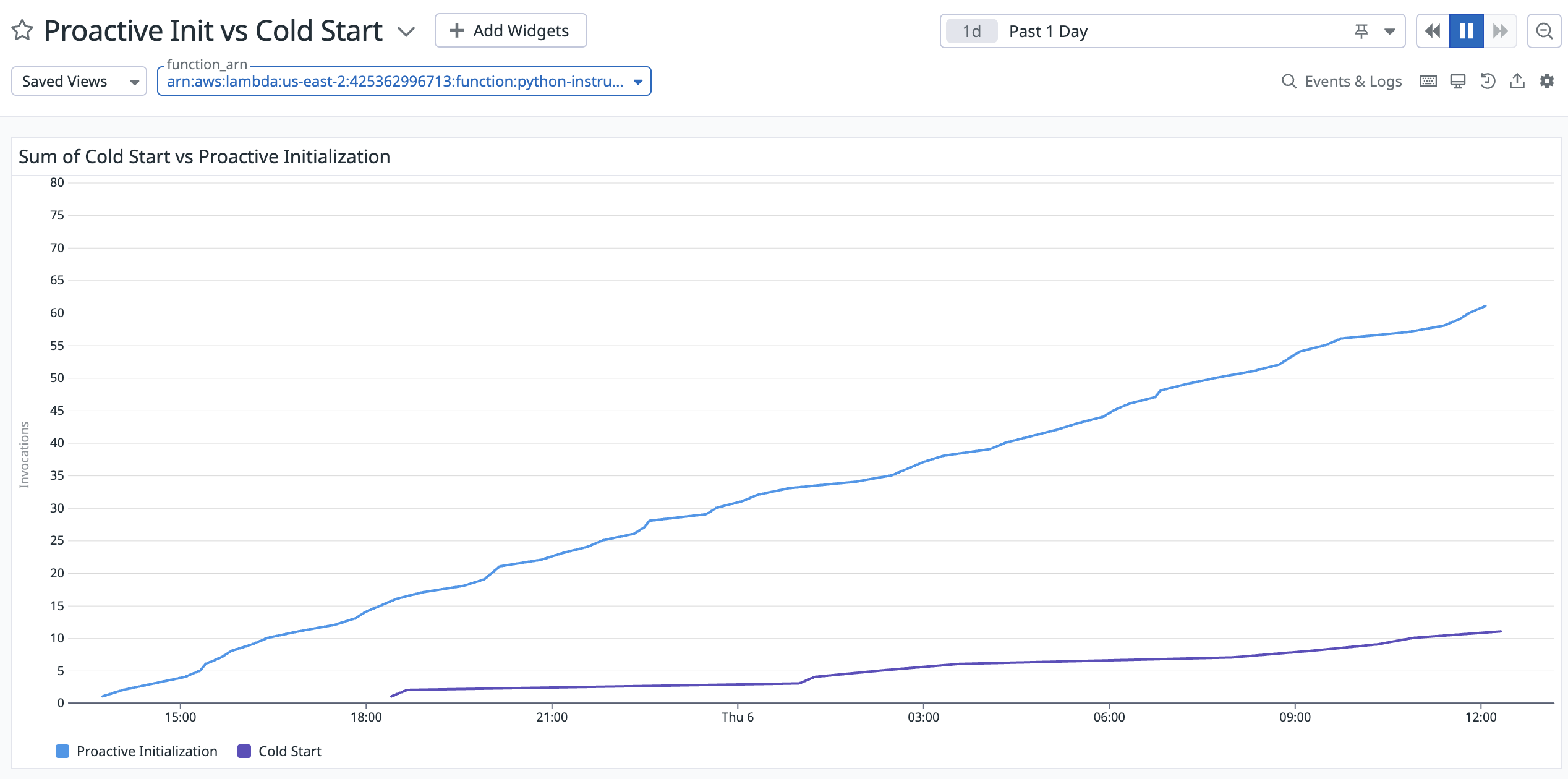
We can see after one day, we’ve had 63 Proactively Initialized Lambda Sandboxes, with only 11 Cold Starts. 85% of initializations were proactive!
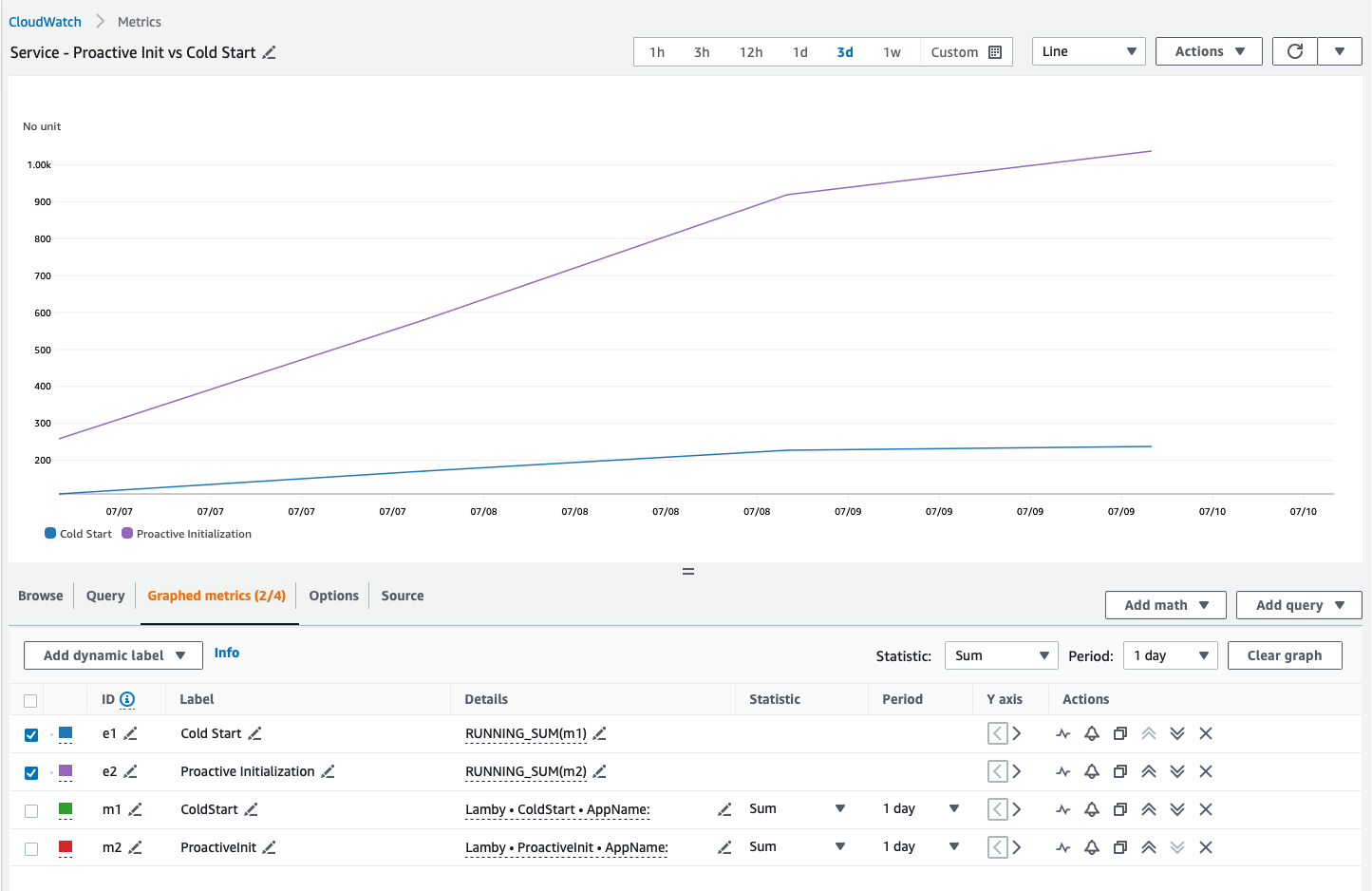
AWS Serverless Hero Ken Collins maintains a very popular Rails-Lambda package. After some discussion, he added the capability to track Proactive Initializations and came to a similar conclusion - in his case after a 3-day test using Ruby with a custom runtime, 80% of initializations were proactive:
Confirming what we suspected
This post confirms what we’ve all speculated but never knew with certainty - AWS Lambda is warming your functions. We’ve demonstrated how you can observe this behavior, and followed this through until the public documentation was updated.
But that begs the question - what should you do about AWS Lambda Proactive Initialization?
What you should do about Proactive Initialization
Nothing.
This is the fulfillment of the promise of Serverless in a big way. You’ll get to focus on your own application while AWS improves the underlying infrastructure. Cold starts become something managed out by the cloud provider, and you never have to think about them.
We use Serverless services because we offload undifferentiated heavy lifting to cloud providers. Your autoscaling needs and my autoscaling needs probably aren’t that similar, but workloads taken in aggregate with millions of functions across thousands of customers, AWS can predictively scale out functions and improve performance for everyone involved.
Wrapping it up
I hope you enjoyed this first look at Proactive Initialization, and learned a bit more about how to observe and understand your workloads on AWS Lambda. If you want to track metrics and/or APM traces for proactively initialized functions, it’s available for anyone using Datadog.
This was also my first post as an AWS Serverless Hero! So if you like this type of content please subscribe to my blog or reach out on twitter with any questions.