How Lambda starts containers 15x faster (deep dive)
We've seen how containers on Lambda initialize as fast or faster than their zip-based counterparts. This post examines exactly how the Lambda team did this, and the performance advantages of everyone shipping the same code.
January 9, 2024
In the first post of this series, we demonstrated that container-based Lambda functions can initialize as fast or faster than zip-based functions. This is counterintuitive as zip-based functions are usually much smaller (up to 250mb), while container images typically contain far more data and are supported up 10gb in size. So how is this technically possible?
“On demand container loading on AWS Lambda” was published on May 23rd, 2023 by Marc Brooker et al. I suggest you read the full paper, as it’s quite approachable and extremely interesting, but I’ll break it down here.
The key to this performance improvement can be summarized in four steps, all performed during function creation.
- Deterministically serialize container layers (which are tar.gz files) onto an ext4 file system
- Divide filesystem into 512kb chunks
- Encrypt each chunk
- Cache the chunks and share them across all customers
With these chunks stored and shared safely in a multi-tier cache, they can be fetched more quicky during function cold start.
But how can one safely encrypt, cache, and share actual bits of a container image between users?!
Container images are sparse
One interesting fact about container images is that they’re an objectively inefficient method for distributing software applications. It’s true!
Container images are sparse blobs, with only a fraction of the contained bytes required to actually run the packaged application. Harter et al found that only 6.5% of bytes on average were needed at startup.
When we consider a collection of container images, the frequency and quantity of similar bytes is very high between images. This means there are lots of duplicated bytes copied over the wire every time you push or pull an image!
This is attributed to the fact that container images include a ton of stuff that doesn’t vary between us as users. These are things like the kernel, the operating system, system libraries like libc or curl, and runtimes like the jvm, python, or nodejs.
Not to mention all of the code in your app which you copied from Chat GPT (like everyone else).
The reality is that we’re all shipping ~80% of the same code.
Deterministic serialization onto ext4
Container images are stacks of tarballs, layered on top of each other to form a filesystem like the one on your own computer. This process is typically done at container runtime, using a storage driver like overlayfs.
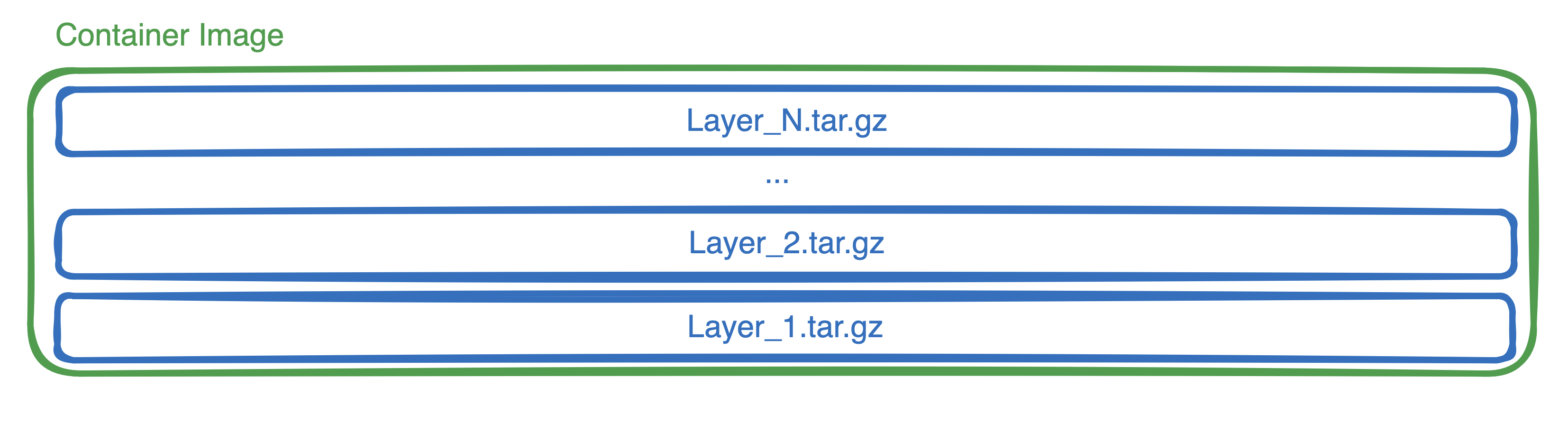
In a typical filesystem, this process of copying files from the tar.gz file to the filesystem’s underlying block device is nondeterministic. Files always land in the same directory, but those locations on disk may land on different parts of the block device over the course of multiple instantiations of the container.
This is a concurrency-based performance optimization used by filesystems, which introduces nondeterminism.
In order to de-duplicate and cache function container images, Lambda also needs a filesystem. This process is done when a function is created or updated. But for Lambda to efficiently cache chunks of a function container image, this process needed to be deterministic. So they made filesystem creation a serial operation, and thus the creation of Lambda filesystem blocks are deterministic.
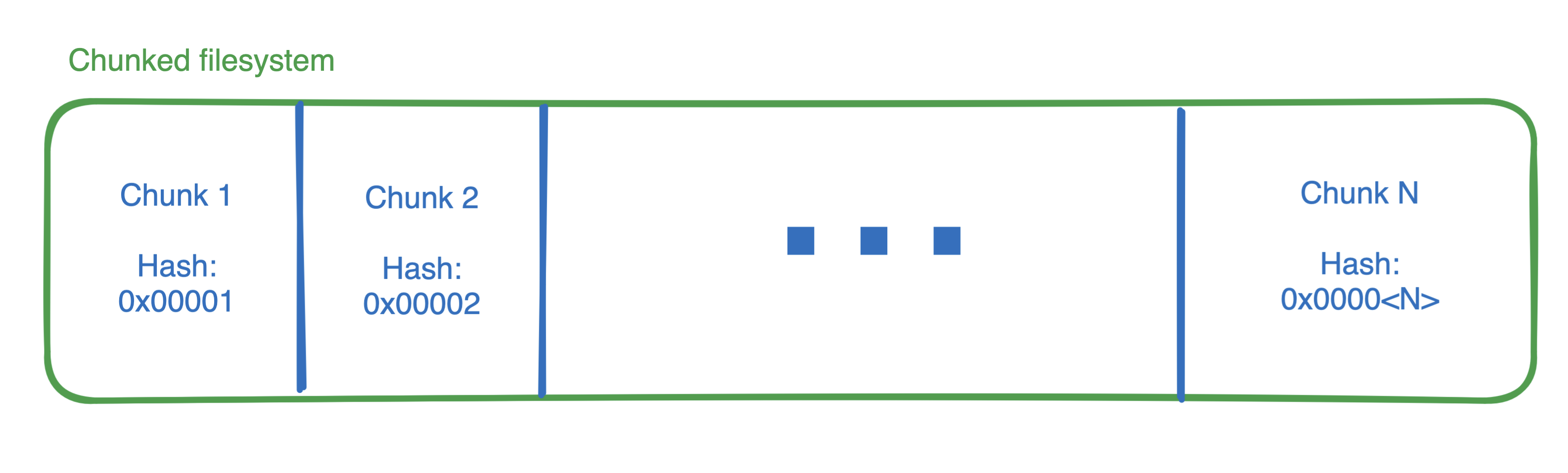
Filesystem chunking
Now that each byte of a container image will land in the same block each time a function is created, Lambda can divide the blocks into 512kb chunks. They specifically call out that larger chunks reduce metadata duplication, and smaller chunks lead to better deduplication and thus cache hit rate, so they expect this exact value to change over time.
The next two steps are the most important.
Convergent encryption
Lambda code is considered unsafe, as any customer can upload anything they want. But then how can AWS deduplicate and share chunks of function code between customers?
The answer is something called Convergent Encryption, which sounds scarier than it is:
- Hash each 512kb chunk, and from that, derive an encryption key.
- Encrypt each block with the derived key.
- Create a manifest file containing a SHA256 hash of each chunk, the key, and file offset for the chunk.
- Encrypt the keys list in the manifest file using a per-customer key managed by KMS.
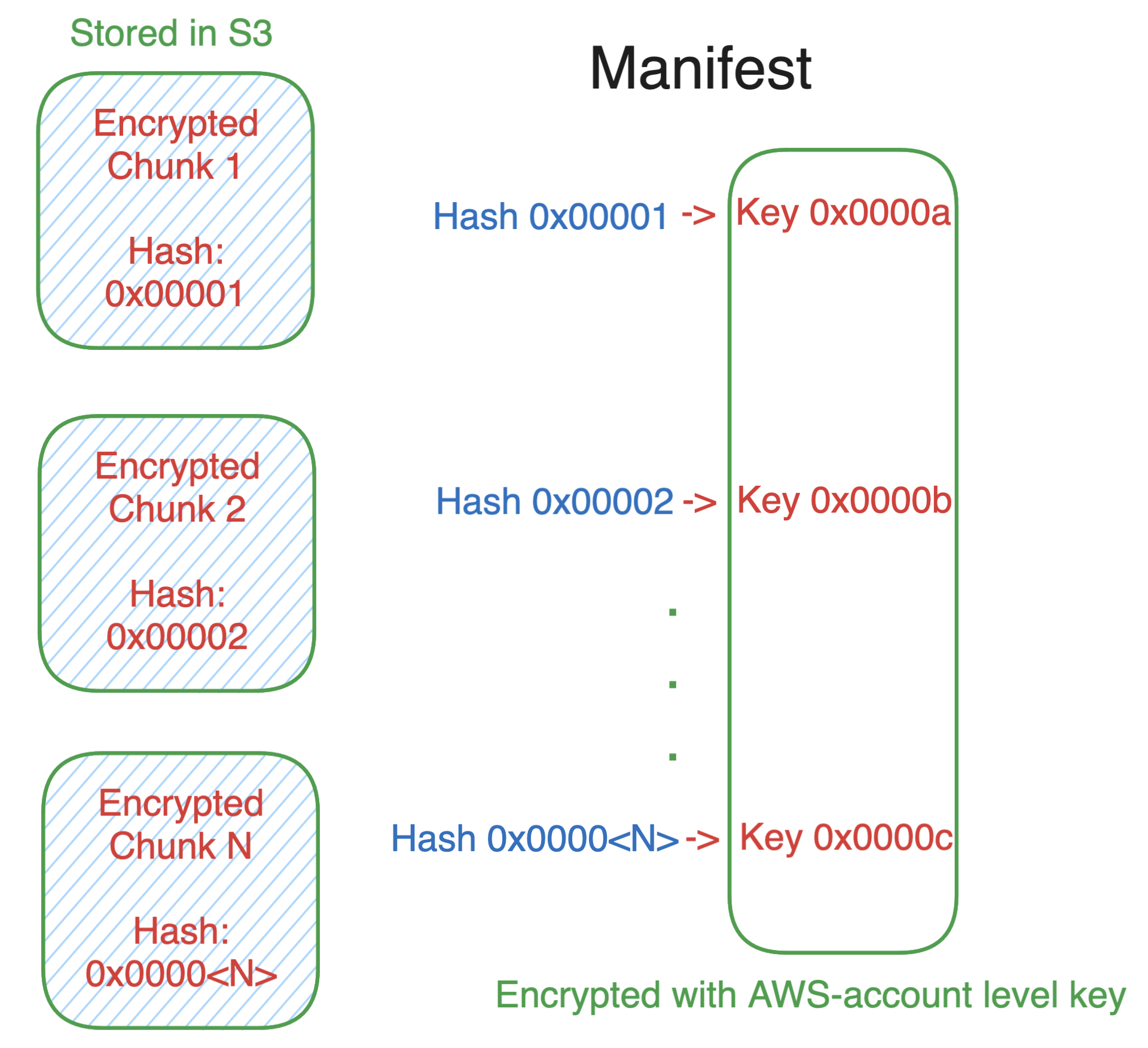
These chunks are then de-duplicated and stored in a s3 when a Lambda function is created.
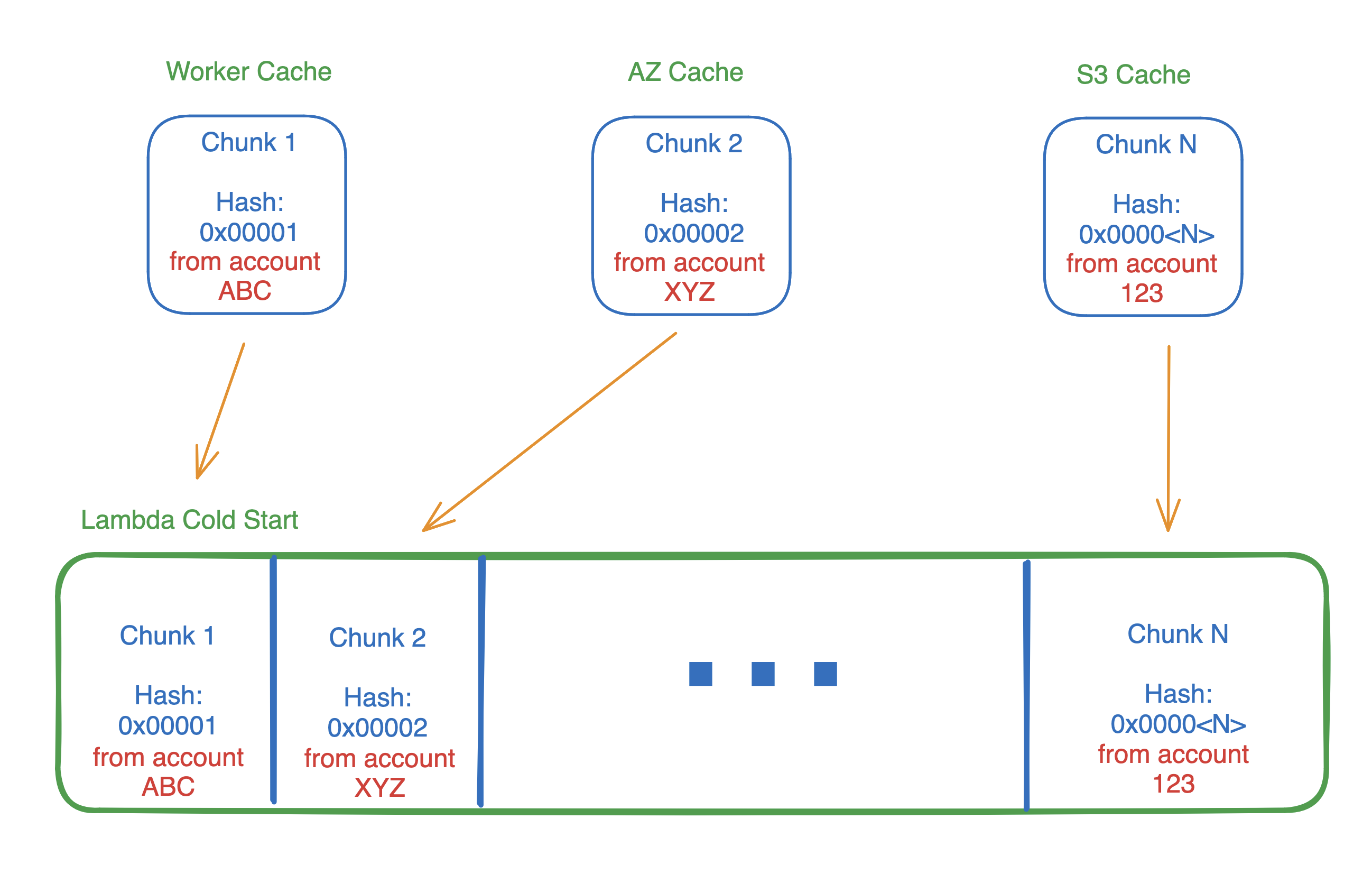
Now that each block is hashed and encrypted, they can be efficiently de-duplicated and shared across customers. The manifest and chunk key list are decrypted by the Lambda worker during a cold start, and only chunks matching those keys are downloaded and decrypted.
This is safe because for any customer’s manifest to contain a chunk hash (and the key derived from it) in the manifest file, that customer’s function must have created and sent that chunk of bytes to Lambda.
Put another way, all users with an identical chunk of bytes also all share the identical key.
This is key to sharing chunks of container images without trust. Now if you and I both run a node20.x container on Lambda, the bytes for nodejs itself (and it’s dependencies like libuv) can be shared, so they may already be on the worker before my function runs or is even created!
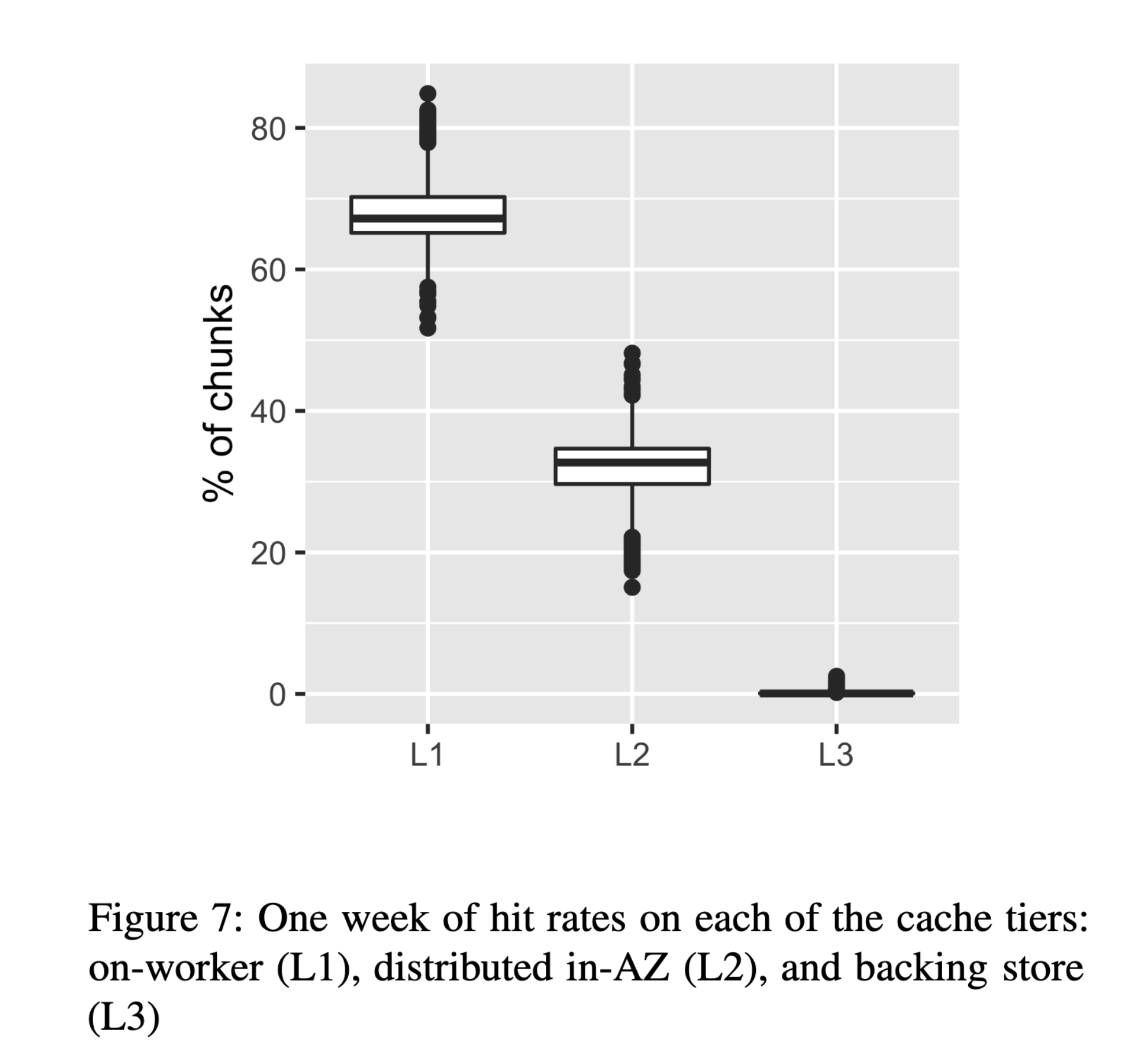
Multi-tiered cache strategy
The last component to this performance improvement is creating a multi-tiered cache. Tier three is the source cache, and lives in an S3 bucket controlled by AWS.
The second tier is an AZ-level cache, which is replicated and separated into an in-memory system for hot data, and flash storage for colder chunks. Fun fact - to reduce p99 outliers, this cache data is stored using erasure coding in a 4-of-5 code strategy. This is the same sharding technique used in s3.
This allows workers to make redundant requests to this cache while fetching chunks, and abandon the slowest request as soon as 4 of the 5 chunks return. This is a common pattern, which AWS also uses when fetching zip-based Lambda function code from s3 (among many other applications).
Finally the tier-one cache lives on each Lambda worker and is entirely in-memory. This is the fastest cache, and most performant to read from when initializing a new Lambda function.
In a given week, 67% of chunks were served from on-worker caches!
Putting it together
During a cold start, these chunk IDs are looked up using the manifest, and then fetched from the cache(s) and decrypted. The Lambda worker reassembles the chunks and then the function initialization begins. It doesn’t matter who uploaded the chunk, they’re all shared safely!
Crazy stat
This leads to a staggering statistic. If (after subscribing and sharing this post), you close this page and create a brand new container-based Lambda function right now, there is an 80% chance that new container image will contain zero unique bytes compared to what Lambda already has seen.
AWS has seen the code and dependencies you are likely to deploy before you have even deployed it.
Wrapping up
The whole paper is excellent and includes many other interesting topics like cache eviction, and how this was implemented (in Rust!), so I suggest you read the full paper to learn more. The Lambda team even had to contend with some cache fragements being too popular, so they had to salt the chunk hashes!
It’s interesting to me that the Fargate team went a totally different direction here with SOCI. My understanding is that SOCI is less effective for images smaller than 1GB, so I’d be curious if some lessons from this paper could further improve Fargate launches.
At the same time, I’m curious if this type of multi-tenant cache would make sense to improve launch performance of something like GCP Cloud Run, or Azure Container Instances.
If you like this type of content please subscribe to my blog or reach out on twitter with any questions. You can also ask me questions directly if I’m streaming on Twitch or YouTube.