Avoiding the Lambda Doom Loop
Heads up serverless developers! A recent change in the Lambda sandbox environment changes how timeouts are handled, potentially causing your function to enter a permanent doom loop. This post will explain the change, how to spot it, and how to avoid the doom loop.
October 3, 2024
There have been a number of recent changes in the Lambda sandbox environment, mostly transparent ones like changing the Runtime API IP address and port to a link-local IP. But recently I noticed a change in how Lambda handles function crashes and re-initialization, and after confirming this behavior with the Lambda team I wanted to take some time to help explain how it works now and why.
In a previous post I’ve demonstrated how not all cold starts are identical. Specifically, cold starts after a runtime crash, function timeout, or out-of-memory error cause the Lambda function to re-initialize and cause a mini cold start, which AWS calls a suppressed init. It’s this case that we’re going to focus on today. As of October 4th, 2024 this is now documented on AWS as well.
If your Lambda functions have an especially short timeout configuration, you’ll want to pay close attention.
Background
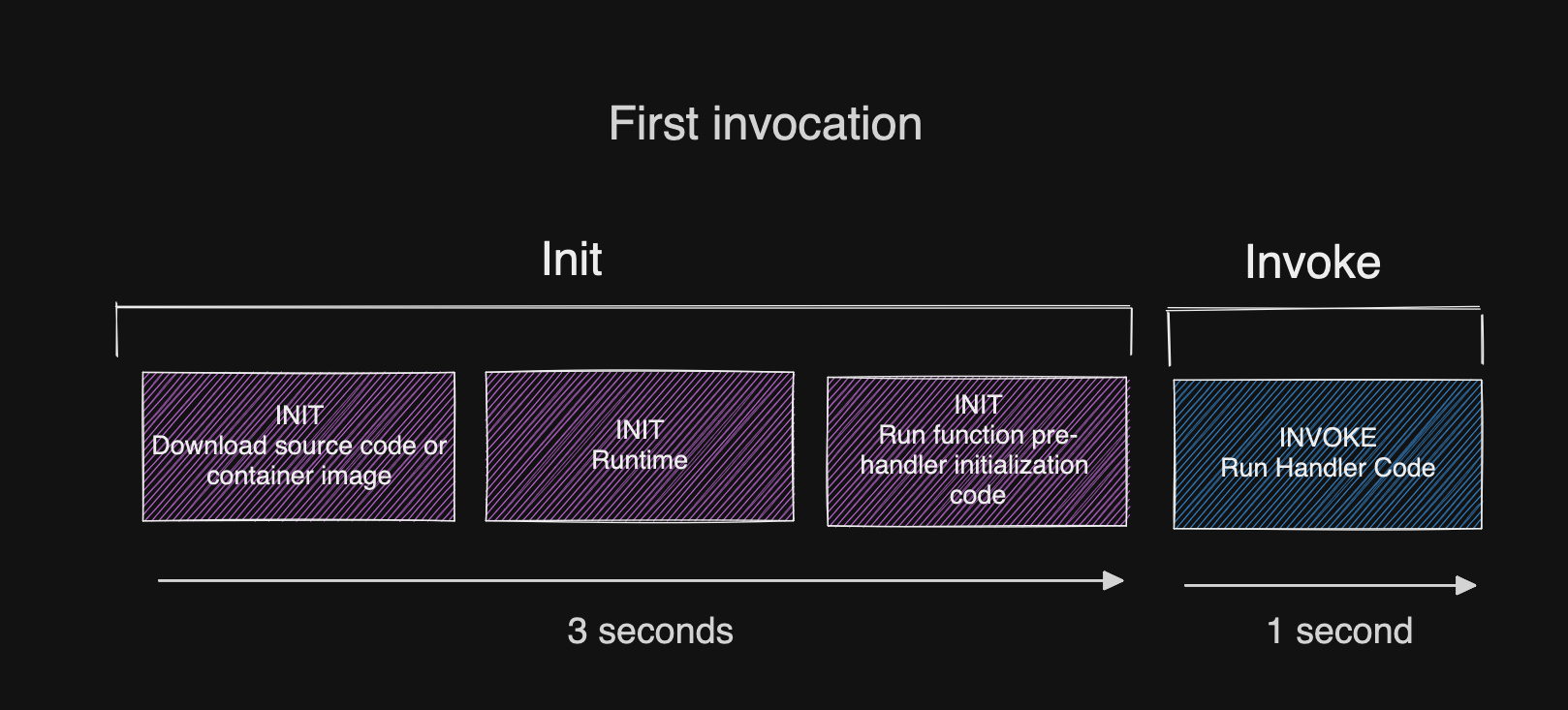
AWS Lambda Functions permit up to 10 seconds for the function code to initialize. Previously we’ve exploited this fact to uncover how AWS pre-warms your function in my post about Proactive Initialization, but it’s important to note that historically, this ten-second init duration is evaluated separately from the configured function timeout.
Today? Apart from the first initialization of a sandbox, re-initialization time for suppressed initializations is counted against the overall function timeout. This may seem myopic, but it can cause a serious downside and outage for your function.
Before your eyes glaze over, let me explain.
Example
Let’s consider a Lambda function serving an API with a 3 second timeout configured. Imagine that the function also requires a database connection along with some credential fetching, so the cold start time is approximately 3 seconds. Today your Lambda function will still initialize successfully after those 3 seconds and go on to serve many other serial Lambda invocations with no issues.
But now imagine that function crashes on the next invocation. Maybe it times out, or runs out of memory.
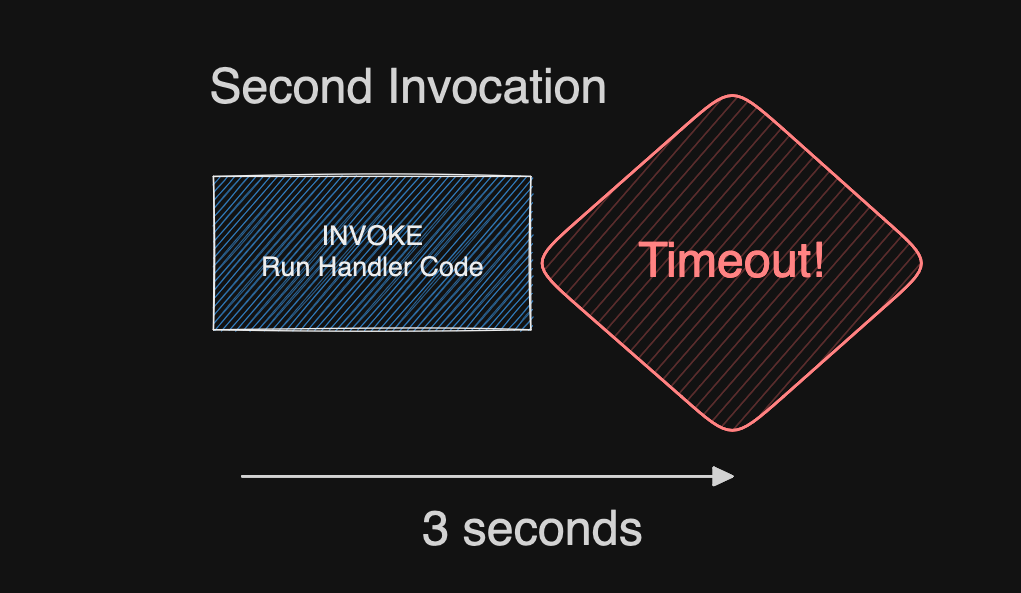
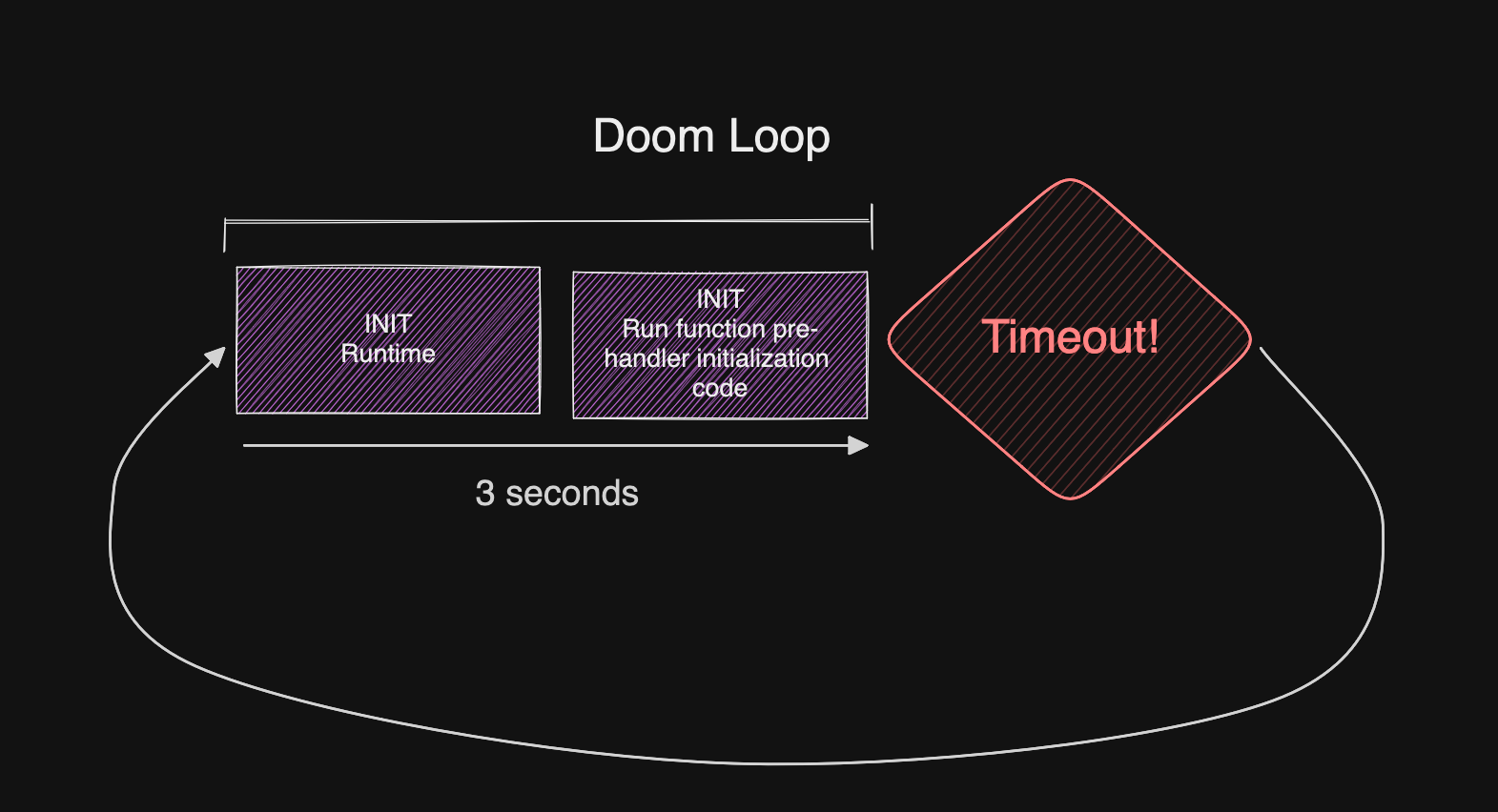
When Lambda re-initializes your function under a suppressed init, it won’t complete re-initialization before the timeout arrives, and it’s now permanently stuck in a retry loop. Function invocations will fail until Lambda decides to kill the sandbox and start a new one.
Reproducing the issue
This one is super easy to reproduce. You can pull down this repo, but the logic is simple:
async function delay(millis) {
return new Promise((resolve) => {
setTimeout(resolve, millis);
});
}
// Simulate a longer init duration
await delay(3000);
console.log('init done');
export async function hello(event) {
if (event.queryStringParameters && event.queryStringParameters.crash) {
// simulate timeout
// After this the function will no longer run, permanently
await delay(5000);
}
return {
statusCode: 200,
body: JSON.stringify({message: 'Hello from Lambda!'})
};
}
- Curl the endpoint to call the function normally. It’ll require 3 seconds to initialize as per the REPORT log:
REPORT RequestId: bdace18c-8f63-48f0-b44a-c909b6b134a0 Duration: 2.85 ms Billed Duration: 3 ms Memory Size: 1024 MB Max Memory Used: 64 MB Init Duration: 3152.18 ms - Force a suppressed init by passing
<url>?crash=true. This causes the function to timeout. - Now call it again, with the
crashparameter removed. The function will continue to crash as it cannot re-initialize. It’s dead until a new sandbox comes along, or you re-deploy the function.
If you open the logs you’ll now see the Status: timeout field, which is new:
REPORT RequestId: 13222b1e-f16b-4550-89df-869ab0a9806d Duration: 3000.00 ms Billed Duration: 3000 ms Memory Size: 1024 MB Max Memory Used: 64 MB Status: timeout
How to avoid the doom loop
Ultimately avoiding this is simple and there are several options.
- Increase the timeout value so it covers the longest possible function execution plus your expected Init Duration time.
- If your function initialization is mostly caused by interpreting code, you can increase the configured memory size up to 1769MB, where you’ll receive one full vCPU.
- Optimize your function initialization! I gave a long talk about this at re:Invent 2023, check it out for specific tips and be sure to consider lazy-loading!
- Finally modify your function code so that a timeout won’t cause the environment to error (and thus re-initialize). You can do this by racing the deadline provided by
getRemainingTimeInMillis()method on the context object.
These tips are in the help docs as well. Although it’s unfortunate this couldn’t be factored in for us when creating Lambda functions, it seems this change is a deeply tied to other intractable changes underpinning Lambda - so it’s one we’ll need to live with.
It’s important to note that this behavior of a suppressed initialization did already exist in some cases earlier. Specifically, beginning around 2021 with functions configured with a Lambda Extension or SnapStart. Now it’s a default behavior for all functions.
Key takeaways
If you’ve followed me for any period of time I hope I’ve given you the tools necessary to minimize the impact of cold starts, but the fact remains that some initialization time is necessary.
This is especially true for customers loading heavy AI or ML libraries, negotiating TCP connections to databases and older caches which don’t offer HTTP APIs like Momento (not sponsored, it’s just good tech). With the recent proliferation of LLMs, I’ve noticed developers choosing to bring heavier libraries to Lambda, so I expect cold start times to be generally longer these days.
If you like this type of content please subscribe to my YouTube channel and follow me on twitter to send me any questions or comments. You can also ask me questions directly if I’m streaming on Twitch.